메모리 위치에 기록 된 정보의 크기가 할당 된 크기를 초과하면 버퍼 오버플로가 발생합니다. 이로 인해 데이터 손상, 프로그램 충돌 또는 악성 코드 실행이 발생할 수 있습니다.
C, C ++ 및 Objective-C는 버퍼 오버 플로우 취약점 (많은 해석 언어보다 메모리를 더 직접적으로 처리하기 때문에)이 있는 주요 언어이지만 인터넷 대부분의 기반입니다.
코드가 Python과 같은 '안전한'언어로 작성 되었더라도 C, C ++ 또는 Objective C로 작성된 라이브러리를 호출하면 여전히 버퍼 오버플로에 취약 할 수 있습니다.
메모리 할당
버퍼 오버플로를 이해하려면 프로그램이 메모리를 할당하는 방법에 대해 조금 이해하는 것이 중요합니다. C 프로그램에서는 컴파일 타임에 스택에, 런타임에 힙에 메모리를 할당 할 수 있습니다.
스택에서 변수를 선언하려면 : int numberPoints = 10;
또는 힙에서 : int * ptr = malloc (10 * sizeof (int));
버퍼 오버 플로우는 스택 (스택 오버 플로우) 또는 힙 (힙 오버 플로우)에서 발생할 수 있습니다.
일반적으로 스택 오버플로는 힙 오버플로 보다 더 일반적으로 악용됩니다. 이는 스택에 중첩 된 함수의 시퀀스가 포함되어 있으며, 각각 함수 실행이 완료된 후 스택이 반환해야 하는 호출 함수의 주소를 반환하기 때문입니다. 이 반환 주소는 대신 악성 코드를 실행하는 명령으로 대체 될 수 있습니다.
힙이 이러한 반환 주소를 덜 일반적으로 저장하기 때문에 익스플로잇을 시작하는 것이 훨씬 더 어렵습니다 (불가능하지는 않지만). 힙의 메모리는 일반적으로 프로그램 데이터를 포함하며 프로그램이 실행될 때 동적으로 할당됩니다. 이것은 힙 오버플로가 함수 포인터를 덮어 써야 할 가능성이 높음을 의미합니다. 스택 오버플로보다 더 어렵고 덜 효과적입니다.
스택 오버플로가 더 일반적으로 악용되는 버퍼 오버플로 유형이므로 정확히 어떻게 작동하는지 간략하게 살펴 보겠습니다.
Stack Overflows
실행 파일이 실행되면 프로세스 내에서 실행되며 각 프로세스에는 자체 스택이 있습니다. 프로세스가 주 함수를 실행함에 따라 새 로컬 변수 (스택 맨 위에 푸시 됨)와 다른 함수 호출 (새 스택 프레임 생성)을 모두 찾습니다.
명확성을 위해 스택 다이어그램 :
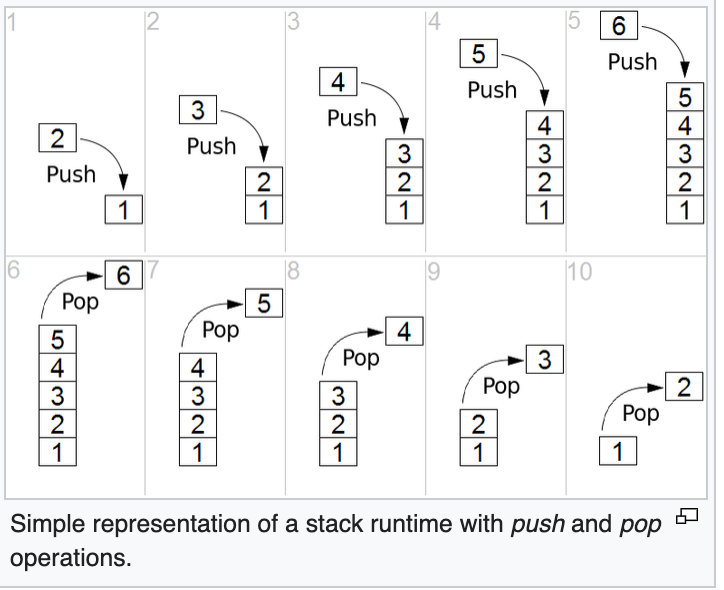
https://en.wikipedia.org/wiki/Stack_(abstract_data_type)
그렇다면 스택 프레임은 무엇입니까?
첫째, 호출 스택은 기본적으로 특정 프로그램에 대한 어셈블러 코드입니다. 컴퓨터에 명령을 실행하는 순서를 알려주는 변수와 스택 프레임의 스택입니다. 아직 실행이 완료되지 않은 각 함수에 대한 스택 프레임이 있으며 현재 실행 중인 함수가 스택 맨 위에 있습니다.
이를 추적하기 위해 컴퓨터는 메모리에 여러 포인터를 유지합니다.
예를 들어 다음 프로그램이 있습니다.
int main() {
int j = firstFunction(5);
return 0;
}
int firstFunction(int z) {
int x = 1 + z;
return x;
}호출 스택은 firstFunction이 호출되고 int x = 1 + z 문이 실행 된 직후 다음과 같습니다.

여기에서 main은 firstFunction (현재 실행 중임)을 호출하므로 호출 스택의 맨 위에 있습니다. 반환 주소는 이를 호출 한 함수의 메모리 주소입니다 (스택 프레임이 생성 될 때 명령어 포인터에 의해 유지됨). 여전히 범위에 있는 지역 변수도 호출 스택에 있습니다. 실행되고 범위를 벗어나면 스택 상단에서 '팝업'됩니다.
따라서 컴퓨터는 어떤 명령을 어떤 순서로 실행해야 하는지 추적 할 수 있습니다. 스택 오버플로는 이러한 저장된 반환 주소 중 하나를 자체 악성 주소로 덮어 쓰도록 설계되었습니다.
버퍼 오버플로 취약점 (C)의 예 :
int main() {
bufferOverflow();
}
bufferOverflow() {
char textLine[10];
printf("Enter your line of text: ");
gets(textLine);
printf("You entered: ", textLine);
return 0;
}이 간단한 예제는 임의의 양의 데이터를 읽습니다 (gets는 파일 끝이나 개행 문자까지 읽습니다). 위에서 살펴본 호출 스택을 생각하면 이것이 왜 위험한지 알 수 있습니다. 사용자가 변수에 할당 된 양보다 더 많은 데이터를 입력하면 사용자가 입력 한 문자열이 호출 스택의 다음 메모리 위치를 덮어 씁니다. 길이가 충분히 길면 호출 함수의 반환 주소를 덮어 쓸 수도 있습니다.
컴퓨터가 이에 반응하는 방식은 스택이 구현되는 방식과 특정 시스템에서 메모리가 할당되는 방식에 따라 다릅니다. 버퍼 오버플로에 대한 응답은 프로그램 오류에서 충돌, 악성 코드 실행에 이르기까지 매우 예측할 수 없습니다.
버퍼 오버플로가 발생하는 이유는 무엇입니까?
버퍼 오버플로가 심각한 문제가 된 이유는 C 및 C ++의 많은 메모리 조작 함수가 경계 검사를 수행하지 않기 때문입니다. 버퍼 오버플로는 현재 잘 알려져 있지만 매우 일반적으로 악용됩니다 (예 : WannaCry가 버퍼 오버플로를 악용).
버퍼 오버플로는 코드가 외부 입력 데이터에 의존하거나 프로그래머가 동작을 쉽게 이해하기에는 너무 복잡하거나 코드의 직접적인 범위를 벗어난 종속성이 있을 때 가장 일반적입니다.
웹 서버, 애플리케이션 서버 및 웹 애플리케이션 환경은 모두 버퍼 오버 플로우에 취약합니다.
예외는 인터프리터 자체가 오버플로에 취약 할 수 있지만 인터프리터 언어로 작성된 환경입니다.
버퍼 오버플로를 완화하는 방법
스택 언더 플로에 대한 참고 사항 :
동일한 프로그램의 두 부분이 동일한 메모리 블록을 다르게 취급 할 때 버퍼 언더 플로 취약점이 있을 수도 있습니다. 예를 들어, 크기 X의 배열을 할당하고 x <X 크기의 배열로 채우고 나중에 모든 X 바이트를 검색하려고 하면 X-x 바이트에 대한 가비지 데이터를 얻을 수 있습니다.
기본적으로 이전에 메모리가 사용 된 방식에서 남은 데이터를 가져 왔을 수 있습니다. 가장 좋은 경우는 아무것도 의미하지 않는 쓰레기라는 것이고, 최악의 경우는 공격자가 오용 할 수 있는 민감한 데이터라는 것입니다.
출처 / 추가 자료 :
https://www.freecodecamp.org/news/buffer-overflow-attacks/
등록된 댓글이 없습니다.