인생에서 우리는 항상 무언가를 찾고 있습니다. 삶의 의미를 찾든 마을에서 가장 맛있는 타코를 찾든, 우리는 답을 얻기 위해 검색 엔진에 크게 의존합니다.
https://dev.to/lisahjung/beginner-s-guide-to-elasticsearch-4j2k

Yelp, Uber 또는 Wikipedia와 같은 가장 강력한 검색 엔진을 매일 사용하고 있을 수 있습니다. 하지만 이러한 검색 엔진이 Elasticsearch로 구축되었다는 사실을 알고 계셨습니까?

Elasticsearch는 모든 유형의 데이터를 위한 분산 오픈 소스 검색 및 분석 엔진입니다. 속도와 확장성으로 유명합니다. 다양한 유형의 콘텐츠를 인덱싱 하는 기능과 결합 된 Elasticsearch는 애플리케이션 검색, 엔터프라이즈 검색, 애플리케이션 성능 모니터링 및 보안 분석과 같은 수많은 사용 사례에 사용됩니다 (Elastic에서 패러 프레이징 됨).
데이터를 실시간으로 대규모로 사용할 수 있도록 하려는 개발자라면 Elasticsearch가 유용한 도구입니다.
Elasticsearch는 Beats, Logstash, Elasticsearch 및 Kibana로 구성된 Elastic Stack의 핵심으로 알려져 있습니다.
함께 Elastic Stack을 사용하면 모든 소스에서 모든 형식의 데이터를 가져온 다음 실시간으로 검색, 분석 및 시각화 할 수 있습니다 (Elastic에서 발췌). 특히 Elasticsearch에 중점을 둘 것입니다.
이 블로그가 끝나면 다음을 수행 할 수 있습니다.
Elastic Stack의 구성 요소는 어떻게 함께 작동하며 앱에 어떻게 통합됩니까?
Elastic 스택은 Beats, Logstash, Elasticsearch 및 Kibana로 구성됩니다.
이러한 구성 요소가 함께 작동하는 방식을 이해하는 가장 좋은 방법은 이러한 구성 요소를 실제 프로젝트의 컨텍스트에 넣는 것입니다. 이러한 구성 요소는 일반적으로 특정 사용 사례를 제공하기 위해 혼합 및 일치됩니다. 이 튜토리얼의 목적을 위해 우리는 그것들을 모두 사용하는 시나리오를 살펴볼 것입니다.
당신이 가장 인기 있는 아웃 도어 장비 전자 상거래 사이트를 책임지는 수석 개발자라고 상상해보십시오. 현재 데이터베이스에 연결된 전체 스택 앱이 있습니다.
수백만 명의 고객이 귀하의 사이트에서 제품을 검색하고 있지만 현재 아키텍처는 사용자가 제출 한 검색어를 따라 잡기 위해 고군분투하고 있습니다.
이것이 Elasticsearch가 들어오는 곳입니다.
 Elasticsearch를 앱에 연결합니다. 사용자가 웹 사이트에서 검색어를 보내면 요청이 서버로 전송됩니다. 서버는 차례로 Elasticsearch에 검색 쿼리를 보냅니다.
Elasticsearch를 앱에 연결합니다. 사용자가 웹 사이트에서 검색어를 보내면 요청이 서버로 전송됩니다. 서버는 차례로 Elasticsearch에 검색 쿼리를 보냅니다.
Elasticsearch는 검색 결과를 서버로 다시 보내고, 서버는 정보를 처리하고 결과를 다시 브라우저로 보냅니다.
이 시점에서 Elasticsearch로 데이터를 가져 오는 방법이 궁금 할 것입니다.
이것이 Beats와 Logstash가 작동하는 곳입니다.
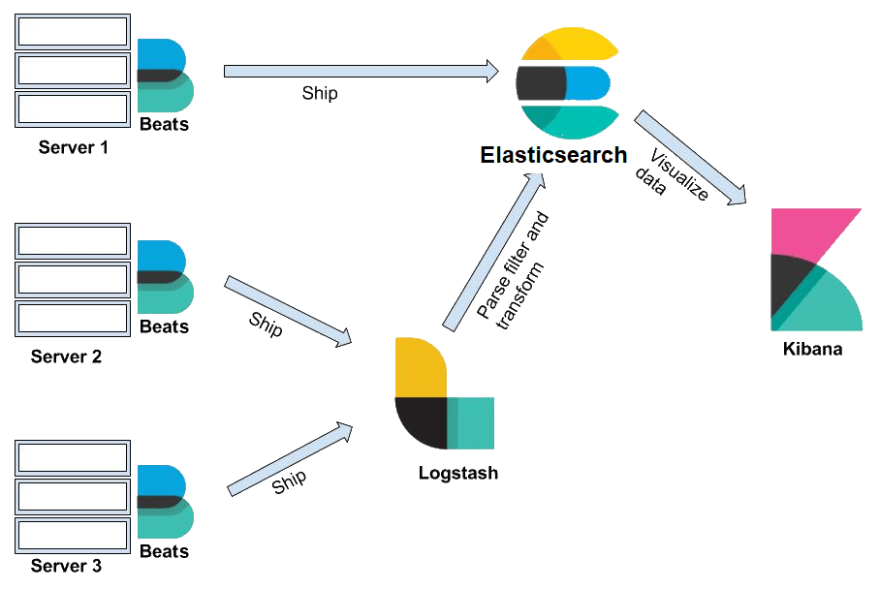
Beats는 데이터 배송 업체의 모음입니다. 서버에 설치되면 데이터를 수집하여 Logstash 또는 Elasticsearch로 보냅니다.
Logstash는 데이터 처리 파이프 라인입니다. logstash가 수신하는 데이터 (예 : 전자 상거래 주문 및 고객 메시지)는 이벤트로 처리됩니다. 이러한 이벤트는 구문 분석, 필터링 및 변환되어 데이터가 저장 될 Elasticsearch로 전송됩니다.
Elasticsearch에서 데이터는 JSON 객체에 저장되는 정보 단위 인 문서로 저장됩니다. REST API는 이러한 문서를 쿼리하는 데 사용됩니다.
Elasticsearch에 대해 조금 더 자세히 살펴 보겠습니다. 지금은 대량의 데이터에 대한 검색 및 분석을 수행하고 있음을 알고 있습니다.
데이터에 대한 모든 검색 및 분석은 데이터를 시각화 하고 그로부터 통찰력을 얻지 못하면 쓸모가 없습니다!
Kibana는 Elasticsearch에 저장된 데이터에 대한 웹 인터페이스를 제공합니다. 사용자는 동일한 REST API를 사용하여 Elasticsearch에 쿼리를 보낼 수 있습니다. 이러한 쿼리는 "매일 사이트를 방문하는 사용자 수"와 같은 질문에 대한 답변을 제공 할 수 있습니다. 또는 지난달 수익은 얼마입니까? "
Kibana 대시 보드를 통해 사용자는 쿼리 결과를 시각화 하고 아래와 같이 데이터에서 통찰력을 얻을 수 있습니다!
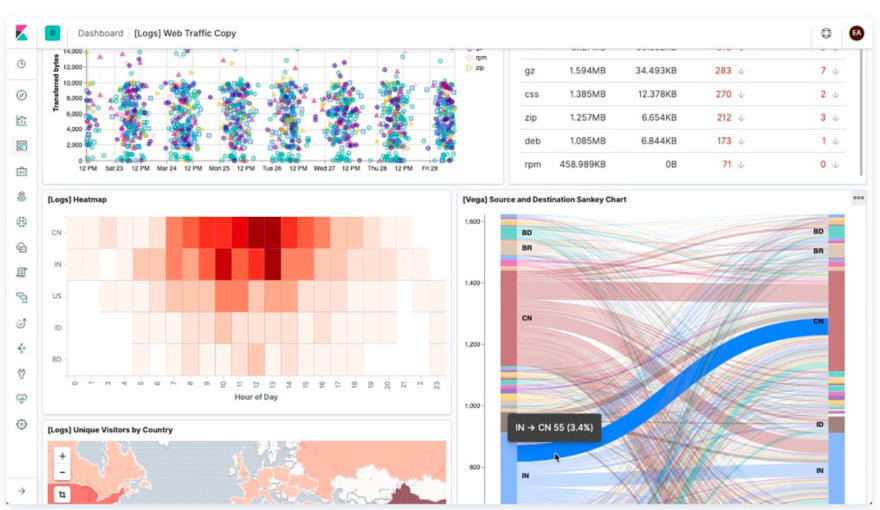
이제 Elastic Stack의 구성 요소가 함께 작동하는 방식을 이해 했으므로 Elasticsearch에 대해 자세히 살펴 보겠습니다!
먼저 Elasticsearch와 Kibana를 설치하여 이 튜토리얼에서 다룰 개념을 시각화 하고 통합 할 것입니다.
Elasticsearch 설치
블로그를 간략하게 유지하기 위해 Windows 용 설치 지침 만 살펴 보겠습니다. 하지만 걱정하지 마세요! 다른 운영 체제의 설치 단계는 매우 유사하며 문제가 발생할 경우 온라인에 많은 설치 비디오가 있습니다.
1 단계 : Elasticsearch 다운로드
다운로드 링크로 이동하십시오.
녹색 상자로 강조 표시된 지역에서 운영 체제에 대한 다운로드 옵션을 선택합니다.

zip 파일이 다운로드 된 것을 볼 수 있습니다 (주황색 상자).
페이지를 아래로 스크롤 하면 설치 단계가 표시됩니다. 이 단계에 지정된 명령을 사용하여 Elasticsearch 서버가 원활하게 실행되는지 테스트합니다.

2 단계 : 다운로드 한 파일 재배치 및 파일 추출
이 파일을 재배치 하는 위치는 사용자에게 달려 있지만 이 자습서에서는 Windows (C :) 드라이브에 Elastic_Stack이라는 폴더를 만들었습니다.
다운로드 한 파일을 Elastic_Stack 폴더로 이동합니다.

파일을 마우스 오른쪽 버튼으로 클릭하여 팝업 옵션을 표시하고 모든 옵션 추출을 클릭하십시오. 파일 압축이 풀리면 파일을 두 번 클릭합니다. 화면에 다음이 표시됩니다.

파일을 두 번 클릭하십시오.
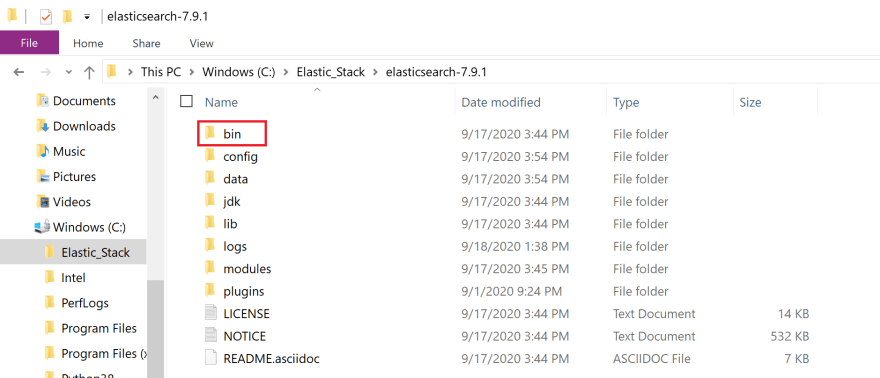
bin 폴더 (빨간색 상자)를 클릭합니다.

녹색 상자로 강조 표시된 영역을 클릭하십시오. bin 폴더의 파일 경로가 표시되어야 합니다. 이 주소를 복사하십시오. 다음 단계에서 사용할 것입니다.
3 단계 : Elasticsearch 서버를 시작하고 모든 것이 제대로 작동하는지 확인

Windows (보라색 상자)에서 명령 프롬프트 앱을 검색하고 관리자 권한으로 실행 옵션 (빨간색 상자)을 클릭합니다.
명령 프롬프트 앱 터미널에서 bin 폴더의 파일 경로를 제공하여 bin 디렉토리 (cd)로 변경하십시오. 이것은 이전 단계에서 복사 한 파일 경로입니다.
#In command prompt terminal
cd filepath to bin folder in Elasticsearch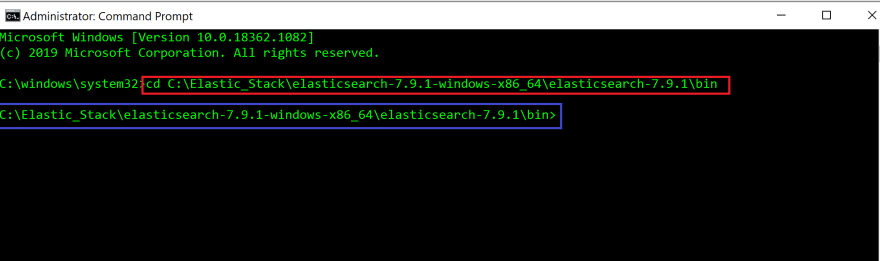
빨간색 상자는 bin 디렉토리로 변경하는 데 사용한 명령을 강조 표시합니다.
Enter를 누르면 bin 디렉토리 (파란색 상자)로 변경된 것을 볼 수 있습니다.
터미널에서 다음 명령을 실행합니다. 윈도우가 아닌 OS에서 실행 중인 경우 대신 터미널에서 elasticsearch를 실행하십시오.
#In command prompt terminal
elasticsearch.batElasticsearch 서버가 실행되는 것을 보기 전에 잠시 커서가 깜박이는 것을 볼 수 있습니다!

Elasticsearch 서버가 포트 9200 (빨간색 상자)의 localhost에서 실행 중인 것을 볼 수 있습니다.
빨리 요약 해 봅시다. 사용자 (클라이언트)가 서버에 요청을 보내면 서버는 Elasticsearch 서버로 검색어를 보냅니다. REST API는 문서를 쿼리 하는 데 사용되며 이 쿼리는 http : // localhost : 9200 엔드 포인트로 전송됩니다.
cURL 명령 줄 도구를 사용하여 Elasticsearch 서버에서 요청을 수신했는지 확인합니다.
새 명령 프롬프트 창 (빨간색 상자)을 엽니다.

새 터미널에서 다음 명령을 실행합니다.
#In new command prompt terminal
curl http://localhost:9200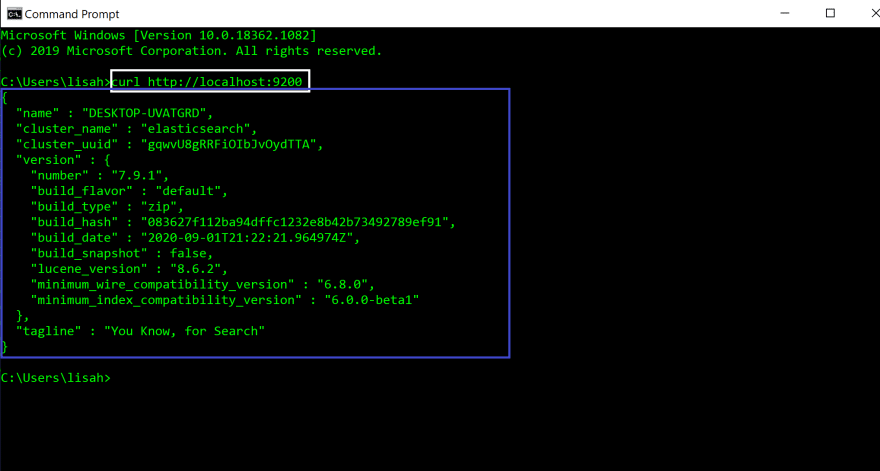
명령 (흰색 상자)을 실행하면 터미널 (파란색 상자)에 다음과 같은 JSON 개체가 표시됩니다. 이는 모든 것이 올바르게 작동하고 Elasticsearch가 성공적으로 설치되었음을 의미합니다.
Elasticsearch 서버를 계속 실행하려면 이 터미널을 열어 두십시오.
Kibana 설치
Kibana 설치는 Elasticsearch 설치와 매우 유사합니다.
1 단계 : Kibana 다운로드
Kibana는 Elasticsearch 용 웹 인터페이스입니다. 그러나 Elasticsearch와 통신하는 백엔드 서버와 함께 제공됩니다.
다운로드 링크로 이동하십시오.
빨간색 상자로 강조 표시된 지역에서 운영 체제에 대한 다운로드 옵션을 선택하십시오.
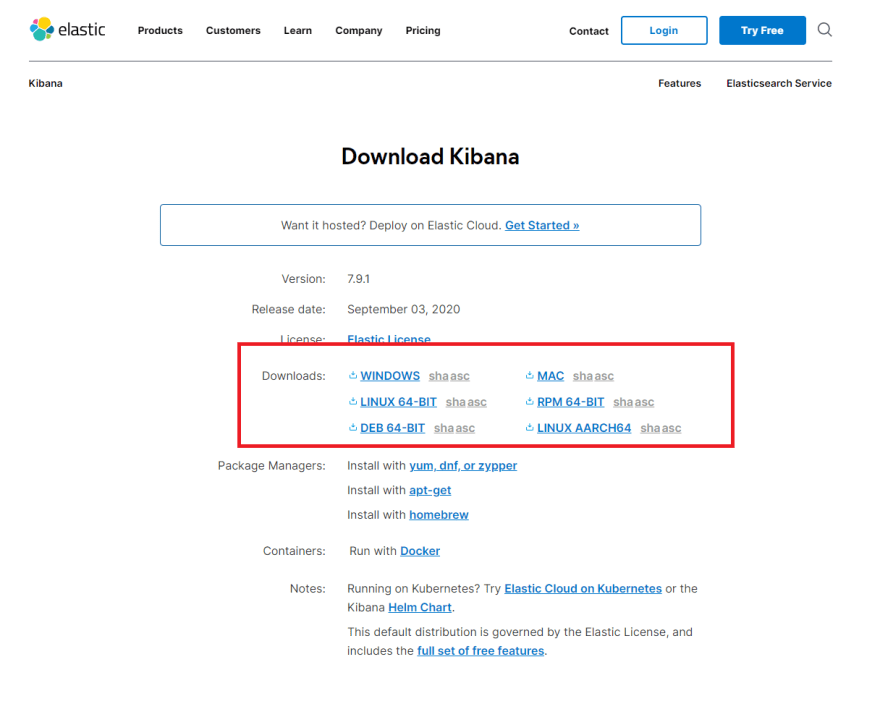 zip 파일이 다운로드 된 것을 볼 수 있습니다.
zip 파일이 다운로드 된 것을 볼 수 있습니다.
페이지를 아래로 스크롤 하면 설치 단계가 표시됩니다. Kibana 서버가 올바르게 실행되고 있는지 테스트하기 위해 이 단계에 지정된 명령을 사용합니다.

2 단계 : 다운로드 한 파일 재배치 및 파일 추출
다운로드 한 파일을 Elastic_Stack 폴더로 이동합니다.
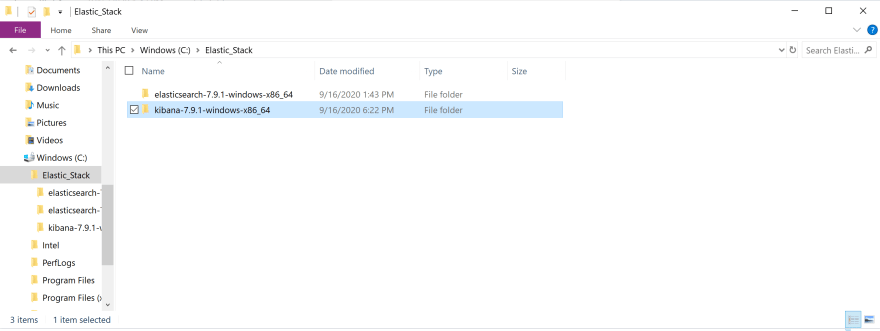
파일을 마우스 오른쪽 버튼으로 클릭하여 옵션을 표시하고 모든 옵션 추출을 클릭하십시오. 파일 압축이 풀리면 파일을 두 번 클릭합니다.

bin 폴더 (빨간색 상자)를 클릭합니다.

녹색 상자로 강조 표시된 영역을 클릭하십시오. bin 폴더의 파일 경로가 표시되어야 합니다. 이 주소를 복사하십시오. 다음 단계에서 사용할 것입니다.
3 단계 : Kibana를 실행하고 모든 것이 제대로 작동하는지 확인
먼저 Elasticsearch 서버를 실행 중인 명령 프롬프트 창으로 돌아갑니다. 아직 실행 중이고 오류 메시지가 표시되지 않는지 확인하십시오.
새 명령 프롬프트 창을 엽니다.
Command Prompt App 터미널에서 bin 폴더의 파일 경로를 제공하여 Kibana의 bin 디렉토리 (cd)로 변경합니다. 이것은 이전 단계에서 bin 폴더에서 복사 한 경로입니다.
#In command prompt terminal
cd filepath to bin folder in Kibana 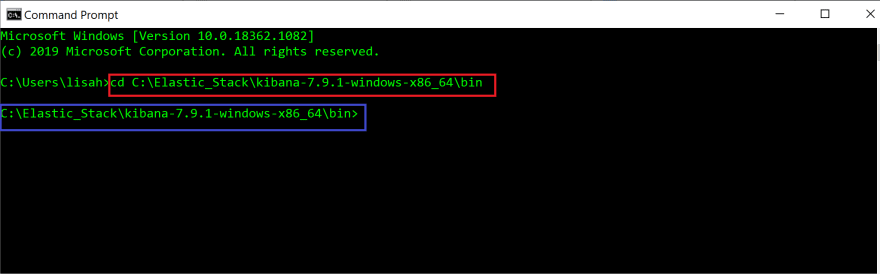
명령이 빨간색 상자로 강조 표시되었습니다.
Enter를 누르면 bin 디렉토리 (파란색 상자)로 변경된 것을 볼 수 있습니다.
터미널에서 다음 명령을 실행합니다. 윈도우가 아닌 OS에서 실행 중인 경우 대신 터미널에서 kibana를 실행하십시오.
#In command prompt terminal
kibana.batKibana가 실행되는 것을 보기 전에 잠시 커서가 깜박이는 것을 볼 수 있습니다!

브라우저를 열고 http : // localhost : 5601로 이동합니다.
브라우저에 다음이 표시됩니다.
문제 해결
If you are having trouble getting Kibana to work, try restarting your Elasticsearch server. Go to the command prompt terminal used for your Elasticserach server. Press `control + c`. Then, run elasticsearch.bat in the same terminal.
Go back to your command prompt terminal for Kibana. Run `control + c` in the command prompt terminal. Then, run kibana.bat in the terminal. Go to http://localhost:5601 on your browser. 좋습니다. Kibana 브라우저로 돌아가겠습니다.

메뉴 옵션 (빨간색 상자)을 클릭하면 드롭 다운 메뉴가 표시됩니다. 관리 섹션으로 스크롤 하여 개발 도구 옵션 (녹색 상자)을 클릭합니다.
이 도구를 사용하면 Elasticsearch에 쿼리를 쉽게 보낼 수 있습니다.
자, 이제 설치를 중단 했으니 Elasticsearch의 기본 아키텍처를 살펴 보겠습니다! Kibana를 사용하여 Elasticsearch의 내부를 살펴볼 것입니다.
Elasticsearch의 기본 아키텍처
Elasticsearch는 분산 된 특성, 속도 및 확장 성으로 유명한 강력한 검색 및 분석 엔진입니다. 이것은 독특한 아키텍처 때문입니다.
엑소 아카이브의 이 다이어그램은 Elasticsearch의 아키텍처를 잘 보여줍니다.

이 다이어그램을 약간 변경하여 이 다이어그램을 한입 크기의 조각으로 나눌 것입니다.

방금 Elasticsearch 서버를 다운로드하여 실행했습니다. 우리가 노드 (주황색 상자)를 시작한다는 것을 거의 알지 못했습니다! 노드는 데이터를 저장하는 Elasticsearch의 실행 인스턴스입니다.
각 노드는 함께 연결된 노드 모음 인 클러스터에 속합니다. 노드를 시작하면 자동으로 클러스터가 형성되었습니다 (녹색 상자).
클러스터에 여러 노드를 추가 할 수 있습니다. 기본적으로 노드에는 마스터 적격, 데이터, 수집 및 기계 학습 (사용 가능한 경우)과 같은 역할이 모두 할당됩니다. 이러한 역할을 구성하고 특정 노드에 특정 역할을 부여 할 수 있습니다.
클러스터의 각 노드는 클라이언트의 HTTP 요청과 노드 간의 통신을 처리 할 수 있습니다. 모든 노드는 동일한 클러스터 내의 동료 노드를 인식하고 요청을 처리하도록 설계된 노드에 HTTP 요청을 전달할 수 있습니다.
데이터는 노드 내에 어떻게 저장됩니까?
Elasticsearch에 저장된 데이터의 기본 단위를 문서라고 합니다. Document는 Elasticsearch에 저장하려는 모든 데이터를 포함하는 JSON 객체입니다.
예를 들어 사용자가 해당 지역에서 최고의 푸드 트럭을 찾는 데 도움이 되는 앱을 구축하고 있다고 가정 해 보겠습니다. 이 앱을 빌드 하려면 푸드 트럭과 이 트럭이 자주 방문하는 위치에 대한 데이터를 저장해야 합니다.
한 푸드 트럭에 대한 데이터를 저장하는 문서는 다음과 같습니다.
{
"name": Pho King Rapidos,
"cuisine": Vietnamese and Mexican fusion
}수백만 대의 푸드 트럭에 대한 데이터가 있다고 상상해보십시오. 데이터를 빠르게 검색하여 찾고 있는 데이터를 찾을 수 있는 방법은 무엇입니까?
데이터 검색은 식료품 점에서 식품을 검색하는 것과 매우 유사합니다. 상점의 모든 식품이 특정 통로 (신선한 농산물, 육류, 유제품, 조미료 등)로 구성되어 있으면 검색이 훨씬 더 효율적입니다.
문서는 비슷한 방식으로 구성됩니다. 모든 문서는 색인 내에 저장됩니다. 색인은 식료품 점의 통로처럼 유사한 특성을 공유하고 논리적으로 서로 관련된 문서 모음입니다.
푸드 트럭 앱의 노드는 다음과 같습니다.

클러스터에는 여러 노드가 포함되어 있습니다. 노드 내에서 관련 문서는 색인 아래에 구성됩니다.
사과를 찾기 위해 농산물 통로로 이동하는 것처럼 문서를 검색 할 때 색인에 대해 검색 쿼리를 실행했습니다.
좋습니다. Elasticsearch의 내부를 살펴보고 방금 생성 한 노드 및 클러스터에 대한 정보를 얻는 방법을 살펴 보겠습니다.
Elasticsearch 클러스터는 HTTP 요청을 수신하는 REST API를 노출합니다. Postman 또는 cURL과 같은 HTTP 클라이언트를 사용하여 이 REST API에 액세스 할 수 있지만 Kibana Dev Tool을 사용하여 이를 수행 할 것입니다.
Kibana Dev Tool을 엽니다. 화면에 다음이 표시되어야 합니다.

클러스터의 상태를 확인하는 것으로 시작하겠습니다.
자체 쿼리를 작성할 수 있도록 회색으로 강조 표시된 영역의 콘텐츠를 삭제합니다.
쿼리 구문은 매우 간단합니다. HTTP 메서드 (GET, POST, PUT, DELETE)를 지정하여 쿼리를 시작합니다. 그런 다음 액세스하려는 API와 수행 할 작업 (명령)을 지정합니다.
이 경우 클러스터의 상태를 검색 (GET)하려고 합니다. 클러스터 API에 액세스 할 것을 지정하고 그 상태에 대한 정보를 원합니다.
따라서 쿼리는 다음과 같아야 합니다.
GET /_cluster/health빨간색 상자로 강조 표시된 영역에 쿼리를 복사하여 붙여 넣습니다.
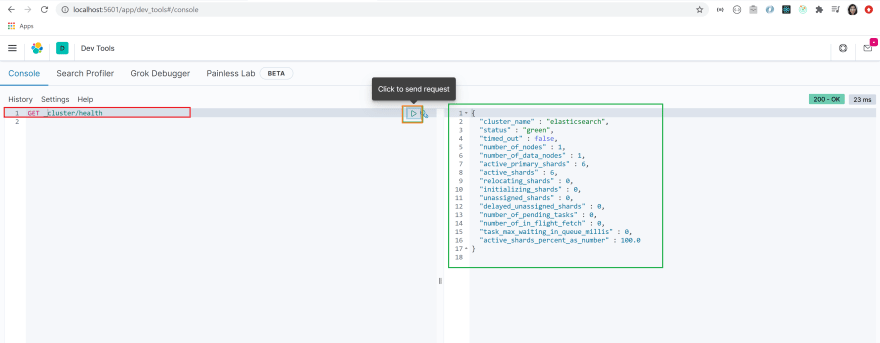
쿼리를 클릭하여 선택했는지 확인하십시오. 주황색 상자로 강조 표시된 화살표를 클릭하여 쿼리를 실행하십시오.
JSON 개체가 반환 된 것을 볼 수 있습니다 (녹색 상자). 클러스터 이름은 기본적으로 elasticsearch로 설정되고 클러스터의 상태는 녹색으로 설정되어 있음을 알 수 있습니다.
이는 클러스터가 정상임을 의미합니다!
클러스터에 있는 노드 목록을 가져 오겠습니다.
이 정보를 얻기 위해 _cat API를 사용합니다. 쿼리 구문은 방금 보낸 쿼리와 매우 유사합니다.
_cat API에 GET 요청을 보내고, nodes? v 명령을 사용하여 클러스터의 노드 목록을 가져옵니다.
쿼리는 다음과 같습니다.
GET /_cat/nodes?v쿼리를 복사하여 dev 도구에 붙여 넣습니다. 쿼리를 선택하고 화살표를 클릭하여 쿼리를 보냅니다.

우리가 가지고 있는 단일 노드에 대한 기본 정보가 화면에 표시되는 것을 볼 수 있습니다. 여기에는 노드의 IP 주소, 이름, 역할 및 일부 성능 측정에 대한 정보가 포함됩니다.
잘 했어! 노드와 클러스터가 성공적으로 생성 된 것 같습니다.
food_trucks에 대한 색인을 생성 해 보겠습니다.
인덱스 이름 뒤에 PUT 메서드를 지정하여 인덱스를 만들 수 있습니다.
개발 도구에서 다음 쿼리를 실행합니다.
PUT food_trucks
반환 된 JSON 개체가 표시됩니다. food_trucks라는 인덱스가 성공적으로 생성되었음을 지정합니다.
또한 shards_acknowledged 값이 true로 설정되어있는 것을 볼 수 있습니다. 곧 다룰 것입니다!
Elasticsearch 아키텍처에 대한 기본적인 이해를 바탕으로 이제 Elasticsearch가 확장 성과 안정성을 높이는 요인이 무엇인지 이해할 준비가 되었습니다!
Elasticsearch의 확장 성 및 안정성이면에있는 요소 이해
샤딩이란?
이전 단계에서 인덱스를 생성 할 때 shards_acknowledged 값이 true로 설정되었음을 확인했습니다. 어쨌든 샤드는 무엇입니까?
Elasticsearch는 확장 성이 매우 뛰어난 것으로 알려져 있습니다. 증가하는 데이터 또는 요구 사항을 지원하도록 적응할 수 있습니다. Elasticsearch의 확장 성을 제공하는 요인 중 하나는 샤딩이라는 관행입니다.
푸드 트럭에 관한 문서가 포함 된 색인에 약 800GB의 데이터가 포함되어 있다고 가정 해 보겠습니다. 클러스터에는 두 개의 노드가 있으며 각 노드에는 데이터 저장에 사용할 수 있는 400GB가 있습니다.

하지만 잠시만 기다려주세요. 전체 색인이 이 노드 중 하나에 맞지 않습니다. 인덱스를 더 작은 청크로 나누고 노드에 저장할 수 있다면 ...
글쎄, 그것이 바로 샤딩입니다! 샤딩은 인덱스를 샤드라고 하는 작은 조각으로 나눕니다. 샤드는 인덱스 데이터의 일부를 포함하며 클러스터 내의 노드에 분산 될 수 있습니다.
따라서 인덱스에 있는 800GB의 데이터는 각각 200GB의 데이터를 보유하는 4 개의 샤드로 나눌 수 있습니다. 그런 다음 이러한 샤드는 노드 1과 2에 분산 될 수 있습니다.
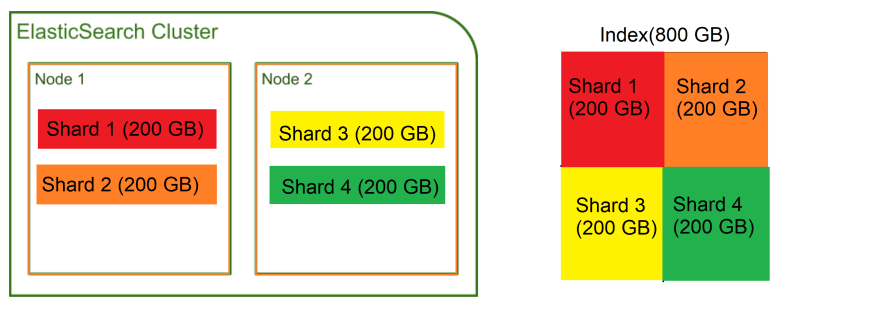
인덱스를 더 작은 샤드로 나누고 노드에 분산함으로써 모든 데이터를 저장할 수 있는 단일 노드가 없다는 사실에도 불구하고 800 기가 바이트의 디스크 공간을 차지하는 인덱스를 저장할 수 있었습니다!
푸드 트럭 앱이 출시되고 사용자 기반이 빠른 속도로 늘어나고 있다고 가정 해 보겠습니다. 수많은 데이터가 저장을 위해 Elasticsearch로 전송되고 있습니다.
더 많은 노드를 추가하고 작업 중인 인덱스에 대한 샤드 수를 변경할 수 있으므로 들어오는 데이터 증가에 대해 걱정할 필요가 없습니다!
복제 란 무엇입니까?
우리의 푸드 트럭 앱은 심각한 추진력을 얻고 있습니다. 공포스럽게도 노드 중 하나가 다운되어 데이터를 어두운 심연으로 내려갑니다.

이런 일을 처리 할 백업 메커니즘이 없다면 이것이 얼마나 악몽이 될지 상상할 수 있습니까?
복제가 있다는 점에 감사드립니다!
Replication는 샤드의 복사본을 만들고 복사본을 다른 노드에 보관합니다. 노드가 다운되면 다른 노드에 저장된 사본이 플레이트로 올라가 아무 일도 일어나지 않은 것처럼 요청을 처리합니다.
Elasticsearch는 아무것도 구성 할 필요 없이 자동으로 샤드를 복제합니다. 인덱스 내 각 샤드의 복사본 (복제 샤드)을 생성합니다.
이전에 food_trucks라는 인덱스를 만든 방법을 기억하십니까? Kibana를 사용하여 인덱스에 대한 자세한 정보를 얻으십시오.
Dev Tool로 이동하여 다음 쿼리를 실행합니다.
GET /_cat/indices?v
열을 보면 pri와 rep (빨간색 상자) 열이 있습니다. 기본 샤드 (pri) 및 복제본 샤드 (rep)를 나타냅니다.
녹색 상자로 강조 표시된 food_trucks 인덱스를 살펴 보겠습니다. 인덱스를 생성하면 기본 샤드와 복제본 샤드가 자동으로 생성되었음을 알 수 있습니다!
Replica 샤드는 pimary 샤드의 동일한 복사본입니다. 기본 샤드와 정확히 동일한 방식으로 작동합니다.
모든 계란을 한 바구니에 넣지 말아야 하므로 복제본 샤드는 기본 샤드와 동일한 노드에 저장되지 않습니다. 기본 샤드 및 복제본 샤드는 아래 표시된 방식으로 노드에 분산됩니다.

노드가 다운 되더라도 다른 노드에 저장된 복제본 샤드가 아무 일도 일어나지 않은 것처럼 여유를 가져 오므로 안심할 수 있습니다!
보시다시피 샤딩과 복제는 Elasticsearch의 확장 성과 안정성에 기여합니다.
좋아요, 우리는 모든 최종 목표를 달성했습니다! 너희들은 여기까지 갈 수 있는 박수와 긴 휴식을 받을 자격이 있다.
이제 Elasticsearch의 중요한 개념을 확실히 이해 했으므로 이제 매핑, 분석 및 고급 쿼리와 같은 고급 기술을 탐색 할 준비가 되었습니다. 직접 Elasticsearch로 무엇을 할 수 있는지 살펴보세요!
등록된 댓글이 없습니다.
{kind=link}