Puppeteer와 Playwright는 테스트, 웹에서 작업 자동화, 스크래핑 등을 위해 Node에서 사용할 수있는 환상적인 고급 브라우저 제어 API입니다. 코드 예제는 이러한 도구로 작업 할 때 항상 유용하며 이 가이드는 이와 관련하여 많은 도움이 됩니다.
Scraping pages
웹 페이지 웹 스크래핑에서 데이터를 추출하는 작업을 호출합니다. 스크래핑은 다양한 사용 사례에 유용합니다.
스크래핑 요소 속성 및 속성
아래는 테스트 사이트에 대해 실행되는 예제로 홈페이지에서 첫 번째 요소의 href 속성을 가져 와서 인쇄합니다. 그것은 바로 우리의 로고이며, 우리 홈페이지로 바로 다시 연결되므로 page.goto()를 사용하여 탐색하는 URL과 동일한 href 값을 갖게 됩니다.
Puppeteer
const puppeteer = require("puppeteer");
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto("https://danube-webshop.herokuapp.com");
const url = await page.$eval("a", (el) => el.href);
console.log(url);
await browser.close();
})();
const { chromium } = require("playwright");
(async () => {
const browser = await chromium.launch();
const page = await browser.newPage();
await page.goto("https://danube-webshop.herokuapp.com");
const url = await page.$eval("a", (el) => el.href);
console.log(url);
await browser.close();
})();
대안으로 ElementHandle을 검색 한 다음 여기에서 속성 값을 검색 할 수도 있습니다. 다음은 홈페이지의 첫 번째 요소의 href 값을 인쇄하는 예입니다.
Puppeteer
const puppeteer = require("puppeteer");
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto("https://danube-webshop.herokuapp.com");
const element = await page.$("a");
const href = await element.evaluate((node) => node.href);
console.log(href);
await browser.close();
})();
Playwright
const { chromium } = require("playwright");
(async () => {
const browser = await chromium.launch();
const page = await browser.newPage();
await page.goto("https://danube-webshop.herokuapp.com");
const element = await page.$("a");
const href = await element.evaluate((node) => node.href);
console.log(href);
await browser.close();
})();
요소 목록 스크래핑
요소 목록을 스크래핑 하는 것도 쉽습니다. 예를 들어 홈페이지에 표시된 각 제품 카테고리의 innerText를 가져와 보겠습니다.
Puppeteer
const puppeteer = require("puppeteer");
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto("https://danube-webshop.herokuapp.com");
const categories = await page.$$eval("li a", (nodes) =>
nodes.map((n) => n.innerText)
);
console.log(categories);
await browser.close();
})();
Playwright
const { chromium } = require("playwright");
(async () => {
const browser = await chromium.launch();
const page = await browser.newPage();
await page.goto("https://danube-webshop.herokuapp.com");
const categories = await page.$$eval("li a", (nodes) =>
nodes.map((n) => n.innerText)
);
console.log(categories);
await browser.close();
})();
이미지 스크랩
페이지에서 이미지를 긁어내는 것도 가능합니다. 예를 들어 테스트 웹 사이트의 로고를 쉽게 가져 와서 파일로 저장할 수 있습니다.
Puppeteer
const puppeteer = require("puppeteer");
const axios = require("axios");
const fs = require("fs");
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto("https://danube-webshop.herokuapp.com");
const url = await page.$eval("img", (el) => el.src);
const response = await axios.get(url);
fs.writeFileSync("scraped-image.svg", response.data);
await browser.close();
})();
Playwright
const { chromium } = require("playwright");
const axios = require("axios");
const fs = require("fs");
(async () => {
const browser = await chromium.launch();
const page = await browser.newPage();
await page.goto("https://danube-webshop.herokuapp.com");
const url = await page.$eval("img", (el) => el.src);
const response = await axios.get(url);
fs.writeFileSync("scraped-image.svg", response.data);
await browser.close();
})();
axios를 사용하여 이미지의 소스 URL에 대해 GET 요청을 합니다. 응답 본문에는 fs를 사용하여 파일에 쓸 수 있는 이미지 자체가 포함됩니다.
스크래핑에서 JSON 생성
더 많은 정보를 스크랩 하기 시작하면 나중에 사용할 수 있도록 표준 형식으로 저장하는 것이 좋습니다. 테스트 사이트의 홈페이지에 나타나는 각 책의 제목, 저자 및 가격을 수집 해 보겠습니다.
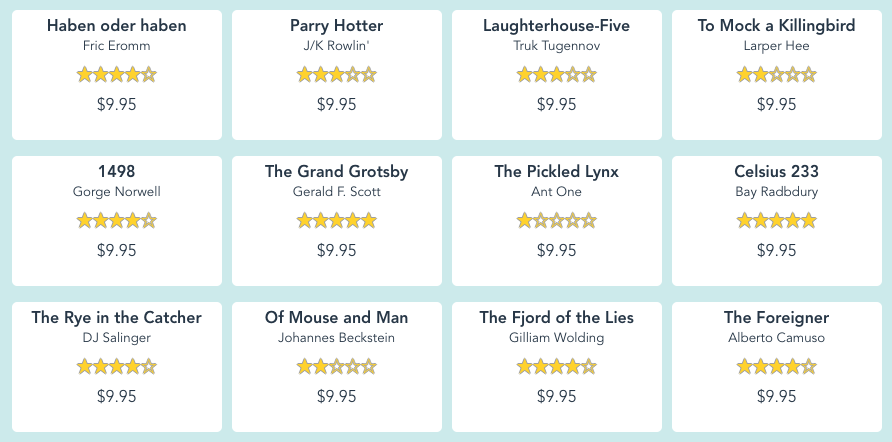
이에 대한 코드는 다음과 같습니다.
Puppeteer
const puppeteer = require("puppeteer");
const fs = require("fs");
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto("https://danube-webshop.herokuapp.com");
const content = await page.evaluate(() => {
let data = [];
let books = document.querySelectorAll(".preview");
books.forEach((book) => {
let title = book.querySelector(".preview-title").innerText;
let author = book.querySelector(".preview-author").innerText;
let price = book.querySelector(".preview-price").innerText;
data.push({
title,
author,
price,
});
});
return data;
});
const jsonData = JSON.stringify(content);
fs.writeFileSync("books.json", jsonData);
await browser.close();
})();
Playwright
const { chromium } = require("playwright");
const fs = require("fs");
(async () => {
const browser = await chromium.launch();
const page = await browser.newPage();
await page.goto("https://danube-webshop.herokuapp.com");
const content = await page.evaluate(() => {
let data = [];
let books = document.querySelectorAll(".preview");
books.forEach((book) => {
let title = book.querySelector(".preview-title").innerText;
let author = book.querySelector(".preview-author").innerText;
let price = book.querySelector(".preview-price").innerText;
data.push({
title,
author,
price,
});
});
return data;
});
const jsonData = JSON.stringify(content);
fs.writeFileSync("books.json", jsonData);
await browser.close();
})();
결과 books.json 파일은 다음과 같습니다.
[
{ "title": "Haben oder haben",
"author": "Fric Eromm",
"price": "$9.95"
},
{
"title": "Parry Hotter",
"author": "J/K Rowlin'",
"price": "$9.95"
},
{
"title": "Laughterhouse-Five",
"author": "Truk Tugennov",
"price": "$9.95"
},
{
"title": "To Mock a Killingbird",
"author": "Larper Hee",
"price": "$9.95"
},
...
]
위의 모든 예제는 다음과 같이 실행할 수 있습니다.
MacOS
node scraping.js
Windows
node scraping.js
등록된 댓글이 없습니다.