Danfo.js는 구조화 된 데이터를 조작하고 처리 할 수 있는 직관적이고 사용하기 쉬운 고성능 데이터 구조를 제공하는 오픈 소스 JavaScript 라이브러리입니다.
Danfo.js는 Python Pandas 라이브러리에서 크게 영감을 받았으며 유사한 인터페이스 / API를 제공합니다. 이는 Pandas API에 익숙하고 JavaScript를 알고 있는 사용자가 쉽게 선택할 수 있음을 의미합니다.
Danfo.js의 주요 목표 중 하나는 JavaScript 개발자에게 데이터 처리, 기계 학습 및 AI 도구를 제공하는 것입니다. 이것은 우리의 비전과 본질적으로 ML을 웹에 가져 오는 TensorFlow.js 팀의 비전과 일치합니다. Numpy 및 Pandas와 같은 오픈 소스 라이브러리는 Python에서 데이터를 쉽게 조작하는 데 혁명을 일으켰고 많은 도구가 이를 기반으로 구축되어 Python에서 버블링하는 ML 생태계를 주도했습니다.
Danfo.js는 TensorFlow.js를 기반으로 합니다. 즉, Numpy가 Pandas 산술 연산을 지원하므로 TensorFlow.js를 활용하여 낮은 수준의 산술 연산을 지원합니다.
Danfo.js의 주요 기능 중 일부
Danfo.js는 빠릅니다. TensorFlow.js를 기반으로 하며 텐서를 즉시 지원합니다. 즉, Danfo에서 Tensor를 로드 하고 Danfo 데이터 구조를 Tensor로 변환 할 수도 있습니다. 이 두 라이브러리를 활용하면 데이터 처리 라이브러리 (Danfo.js)와 강력한 ML 라이브러리 (TensorFlow.js)가 있습니다.
아래 예에서는 텐서 객체에서 Danfo DataFrame을 생성하는 방법을 보여줍니다.
const dfd = require("danfojs-node")
const tf = require("@tensorflow/tfjs-node")
let data = tf.tensor2d([[20,30,40], [23,90, 28]])
let df = new dfd.DataFrame(data)
let tf_tensor = df.tensor
console.log(tf_tensor);
tf_tensor.print()Output:
Tensor {
kept: false,
isDisposedInternal: false,
shape: [ 2, 3 ],
dtype: 'float32',
size: 6,
strides: [ 3 ],
dataId: {},
id: 3,
rankType: '2'
}
Tensor
[[20, 30, 40],
[23, 90, 28]]조작을 위해 배열, JSON 또는 객체를 DataFrame 객체로 쉽게 변환 할 수 있습니다.
JSON object to DataFrame:
const dfd = require("danfojs-node")
json_data = [{ A: 0.4612, B: 4.28283, C: -1.509, D: -1.1352 },
{ A: 0.5112, B: -0.22863, C: -3.39059, D: 1.1632 },
{ A: 0.6911, B: -0.82863, C: -1.5059, D: 2.1352 },
{ A: 0.4692, B: -1.28863, C: 4.5059, D: 4.1632 }]
df = new dfd.DataFrame(json_data)
df.print()Output:

DataFrame에 대한 열 레이블이 있는 개체 배열 :
const dfd = require("danfojs-node")
obj_data = {'A': [“A1”, “A2”, “A3”, “A4”],
'B': ["bval1", "bval2", "bval3", "bval4"],
'C': [10, 20, 30, 40],
'D': [1.2, 3.45, 60.1, 45],
'E': ["test", "train", "test", "train"]
}
df = new dfd.DataFrame(obj_data)
df.print()Output:

부동 소수점 데이터 뿐만 아니라 부동 소수점 데이터에서도 누락 된 데이터 (NaN로 표시됨)를 쉽게 처리 할 수 있습니다.
const dfd = require("danfojs-node")
let data = {"Name":["Apples", "Mango", "Banana", undefined],
"Count": [NaN, 5, NaN, 10],
"Price": [200, 300, 40, 250]}
let df = new dfd.DataFrame(data)
let df_filled = df.fillna({columns: ["Name", "Count"], values: ["Apples",
df["Count"].mean()]})
df_filled.print()Output:
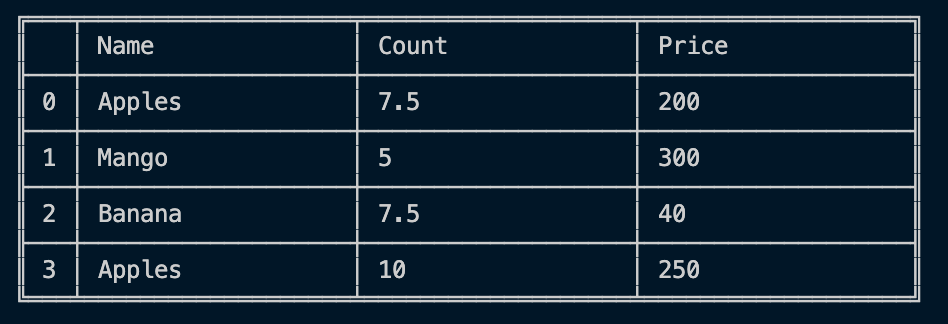
지능형 레이블 기반 슬라이싱, 고급 인덱싱 및 대규모 데이터 세트 쿼리 :
const dfd = require("danfojs-node")
let data = { "Name": ["Apples", "Mango", "Banana", "Pear"] ,
"Count": [21, 5, 30, 10],
"Price": [200, 300, 40, 250] }
let df = new dfd.DataFrame(data)
let sub_df = df.loc({ rows: ["0:2"], columns: ["Name", "Price"] })
sub_df.print()Output:
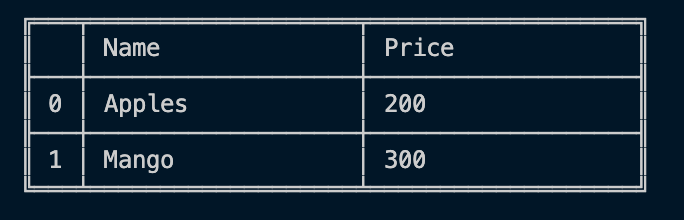
플랫 파일 (CSV 및 구분)에서 데이터를로드하기위한 강력한 IO 도구. 전체 및 청크 모두 :
const dfd = require("danfojs-node")
//read the first 10000 rows
dfd.read_csv("file:///home/Desktop/bigdata.csv", chunk=10000)
.then(df => {
df.tail().print()
}).catch(err=>{
console.log(err);
})OneHotEncoders, LabelEncoders와 같은 강력한 데이터 전처리 기능과 StandardScaler 및 MinMaxScaler와 같은 스케일러는 DataFrame 및 Series에서 지원됩니다.
const dfd = require("danfojs-node")
let data = ["dog","cat","man","dog","cat","man","man","cat"]
let series = new dfd.Series(data)
let encode = new dfd.LabelEncoder()
encode.fit(series)
let sf_enc = encode.transform(series)
let new_sf = encode.transform(["dog","man"])Output:

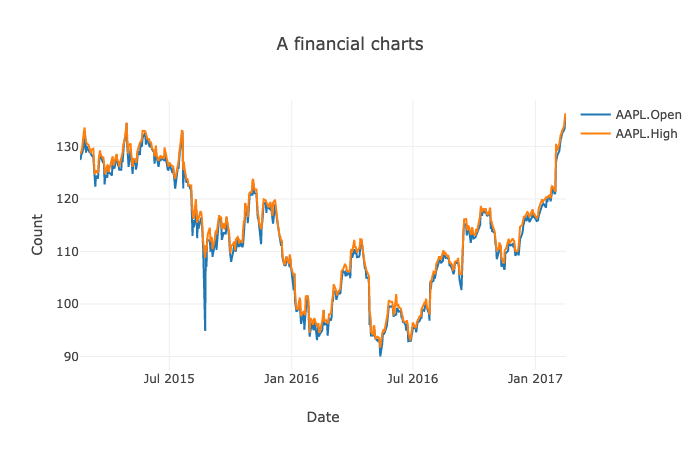
브라우저에서 DataFrame 및 Series를 플로팅 하기 위한 대화 형의 유연하고 직관적 인 API :
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<script src="https://cdn.jsdelivr.net/npm/danfojs@0.1.1/dist/index.min.js"></script>
<title>Document</title>
</head>
<body>
<div id="plot_div"></div>
<script>
dfd.read_csv("https://raw.githubusercontent.com/plotly/datasets/master/finance-charts-apple.csv")
.then(df => {
var layout = {
title: 'A financial charts',
xaxis: {title: 'Date'},
yaxis: {title: 'Count'}
}
new_df = df.set_index({ key: "Date" })
new_df.plot("plot_div").line({ columns: ["AAPL.Open", "AAPL.High"], layout: layout
})
}).catch(err => {
console.log(err);
})
</script>
</body>
</html>Output:
Danfo.js 및 Tensorflow.js를 사용한 타이타닉 생존 예측
아래는 Danfo.js 및 TensorFlow.js를 사용하는 간단한 엔드 투 엔드 분류 작업을 보여줍니다. 데이터 로드, 데이터 세트의 조작 및 전처리에 Danfo를 사용한 다음 텐서 객체를 내 보냅니다.
const dfd = require("danfojs-node")
const tf = require("@tensorflow/tfjs-node")
async function load_process_data() {
let df = await dfd.read_csv("https://web.stanford.edu/class/archive/cs/cs109/cs109.1166/stuff/titanic.csv")
//A feature engineering: Extract all titles from names columns
let title = df['Name'].apply((x) => { return x.split(".")[0] }).values
//replace in df
df.addColumn({ column: "Name", value: title })
//label Encode Name feature
let encoder = new dfd.LabelEncoder()
let cols = ["Sex", "Name"]
cols.forEach(col => {
encoder.fit(df[col])
enc_val = encoder.transform(df[col])
df.addColumn({ column: col, value: enc_val })
})
let Xtrain,ytrain;
Xtrain = df.iloc({ columns: [`1:`] })
ytrain = df['Survived']
// Standardize the data with MinMaxScaler
let scaler = new dfd.MinMaxScaler()
scaler.fit(Xtrain)
Xtrain = scaler.transform(Xtrain)
return [Xtrain.tensor, ytrain.tensor] //return the data as tensors
}다음으로 TensorFlow.js를 사용하여 간단한 신경망을 만듭니다.
function get_model() {
const model = tf.sequential();
model.add(tf.layers.dense({ inputShape: [7], units: 124, activation: 'relu', kernelInitializer: 'leCunNormal' }));
model.add(tf.layers.dense({ units: 64, activation: 'relu' }));
model.add(tf.layers.dense({ units: 32, activation: 'relu' }));
model.add(tf.layers.dense({ units: 1, activation: "sigmoid" }))
model.summary();
return model
}마지막으로 먼저 모델과 처리 된 데이터를 텐서로 로드 하여 학습을 수행합니다. 이것은 신경망에 직접 공급 될 수 있습니다.
async function train() {
const model = await get_model()
const data = await load_process_data()
const Xtrain = data[0]
const ytrain = data[1]
model.compile({
optimizer: "rmsprop",
loss: 'binaryCrossentropy',
metrics: ['accuracy'],
});
console.log("Training started....")
await model.fit(Xtrain, ytrain,{
batchSize: 32,
epochs: 15,
validationSplit: 0.2,
callbacks:{
onEpochEnd: async(epoch, logs)=>{
console.log(`EPOCH (${epoch + 1}): Train Accuracy: ${(logs.acc * 100).toFixed(2)},
Val Accuracy: ${(logs.val_acc * 100).toFixed(2)}\n`);
}
}
});
};
train()독자는 Danfo의 API가 Pandas와 매우 유사하며 자바 스크립트가 아닌 프로그래머가 코드를 쉽게 읽고 이해할 수 있음을 알게 될 것입니다. 여기에서 데모의 전체 소스 코드를 찾을 수 있습니다 (https://gist.github.com/risenW/f54e4e5b6d92e7b1b9b1f30e884ca83c).
맺음말
웹 기반 기계 학습이 성숙 해짐에 따라 이를 위해 특별히 구축 된 효율적인 데이터 과학 도구를 갖추는 것이 필수적입니다. Danfo.js와 같은 도구를 사용하면 웹 기반 애플리케이션이 ML 기능을 쉽게 지원할 수 있으므로 흥미 진진한 애플리케이션 생태계에 대한 공간이 열립니다. TensorFlow.js는 Python에서 사용할 수 있는 ML 기능을 제공함으로써 혁명을 시작했으며 Danfo.js가 이 여정에서 효율적인 파트너가 되기를 바랍니다. Danfo.js가 어떻게 성장하는지 기다릴 수 없습니다! 바라건대, 웹 커뮤니티에도 없어서는 안될 것입니다.
등록된 댓글이 없습니다.