Node는 가볍고 확장 가능하며 빠르게 개발할 수 있으며 npm에는 놀라운 패키지가 있습니다.
HarperDB의 창립 팀은 Node.js로 작성된 최초이자 유일한 데이터베이스를 구축했습니다. 몇 달 전, CEO Stephen Goldberg는 Women Who Code 밋업에서 이 (일부는 미친 짓이라고 부르는) 노력에 대한 이야기를 공유하도록 초대되었습니다. Stephen은 데이터베이스의 아키텍처 계층에 대해 논의하고 Node.js에서 확장 성이 뛰어난 분산 제품을 빌드 하는 방법을 시연하고 HarperDB의 내부 작업을 시연했습니다. 위 링크에서 그의 강연을 볼 수 있고 2017 년의 게시물을 읽을 수도 있지만 우리 모두가 Node.js를 좋아하고 흥미로운 주제이므로 여기에 요약하겠습니다.
https://dev.to/harperdb/building-a-database-written-in-node-js-from-the-ground-up-2hgm
Node에서 데이터베이스를 구축하기로 선택한 주된 (그리고 가장 간단한) 이유는 우리가 정말 잘 알고 있었기 때문입니다. 우리는 Go를 선택하지 않은 것에 대해 약점을 얻었지만 이제 사람들은 Go와 Node가 본질적으로 정면 대결이라는 것을 받아들입니다. 공동 창립자 중 한 명인 Zach는 새로운 언어를 배우는 데 시간이 걸리면 그만한 가치가 없다는 것을 깨달았습니다.
Node.js에서 데이터베이스 구축의 장점
HarperDB 팀은 대규모 소프트웨어 개발에 대한 배경 지식을 가지고 있습니다. 데이터베이스의 초기 목표는 개발자가 데이터베이스 유지 관리에 시간과 노력을 들이지 않고도 코딩에 집중할 수 있는 도구를 만드는 동시에 강력한 솔루션을 제공하는 것이었습니다. 우리는 사람들이 사용 중인 제품에 대해 편안하고 자신감을 갖기를 원했습니다.
우리 팀은 Node 이외의 언어에 대한 광범위한 경험을 가지고 있지만 프로그래밍에 큰 성공을 거두었습니다. (Java에서 왔지만 Stephen은 Node가 처음에는 끔찍하다고 생각했지만 약 90 일 후에 그는 그것을 좋아하는 법을 배웠습니다.) 노드는 가볍고 빠르게 개발할 수 있으며 npm에는 놀라운 패키지가 있습니다.
Node.js에서 데이터베이스 구축의 단점
몇 가지 문제가 있었습니다. Node.js로 작성된 최초의 데이터베이스이기 때문에 누구의 발자취도 따라갈 수 있는 옵션이 없었습니다.
우리는 아마도 Node에 구축 된 최초의 엔터프라이즈 제품 중 하나이며 최소한 가장 데이터 중심적인 제품 일 것입니다. 사람들은 이것을 의심했습니다. 한 사람은 스티븐에게 Node.js에서 데이터베이스를 프로그래밍 하는 것보다 숟가락으로 심장을 잘라 내고 싶다고 말했습니다. 이제 사람들은 이것이 훌륭한 아이디어라는 것을 깨달았습니다. 우리 제품에는 우리가 구축 할 필요가 없고 우리가 하는 일에 내재되어있는 놀라운 기능이 모두 포함되어 있기 때문입니다. 파일 시스템에서 OS를 직접 제어하지 못하는 문제에 부딪혔습니다. 또한 C / C ++는 더 빠르지 만 더 복잡할 수 있으며 반드시 수평으로 확장 할 수 있는 것은 아닙니다. 수직 또는 수평 컴퓨팅을 찾고 있는지 여부에 따라 다릅니다.
Tech Stack
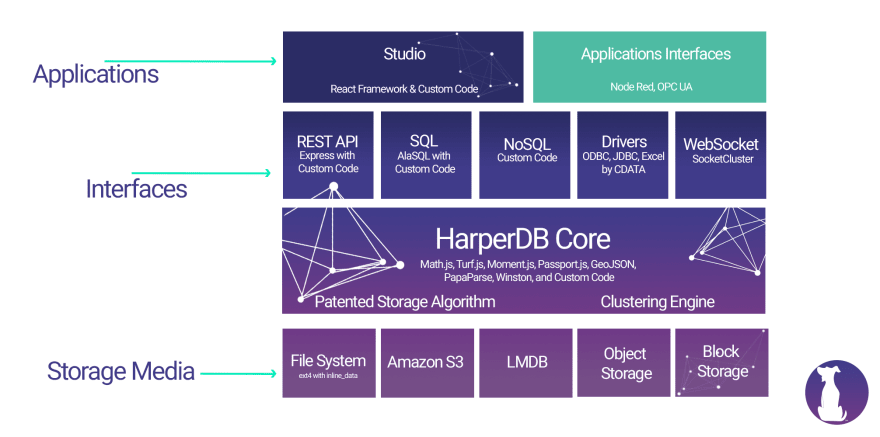
이것이 우리 기술 스택의 모습입니다. 우리는 Management Studio를 HarperDB 스택의 일부로 간주하며 이는 노드 백엔드와 함께 React에 구축됩니다. 녹색 상자는 HarperDB 위에 구축 된 모든 애플리케이션을 나타냅니다. 예를 들어 Node-RED 노드를 사용하여 사용자 지정 워크 플로를 구축 할 수 있습니다. HarperDB 기술은 인터페이스와 HarperDB 코어를 포함하는 Node.js로 전적으로 구축되었습니다.
우리 제품은 내부적으로는 기본적으로 Express 애플리케이션 인 REST API로 나타나며 HarperDB와 상호 작용하는 방법에 대한 기본 인터페이스입니다. NoSQL 파서는 내부적으로 구축 한 맞춤형 솔루션입니다. 여기에서 자세히 읽을 수 있는 SQL 구문 분석 기능에 AlaSQL을 사용하고 그 위에 사용자 지정 코드로 기능을 확장합니다. SQL 구문 분석을 위한 놀라운 npm 패키지입니다. 우리의 파트너가 만든 ODBC 및 JDBC와 같은 드라이버를 제공합니다. 마지막으로, 분산 컴퓨팅 및 클러스터링을 위해 SocketCluster를 사용합니다. CTO는 몇 주 후에 발표 할 예정입니다.
HarperDB 핵심 기술은 "비밀 소스"를 포함합니다. 따라서 데이터 중복 없이 완전히 인덱싱 되고 단일 데이터 모델에 다양한 인터페이스 옵션을 제공 할 수 있습니다. 코어 내에는 기능을 확장하기 위해 구현 된 수많은 npm 패키지가 있습니다.
마지막으로 저장 매체에 대한 다양한 옵션이 있습니다. 다른 옵션에 비해 상당한 성능 향상을 제공하므로 기본적으로 LMDB를 번들로 제공합니다. HarperDB 코어에는 향후 추가 스토리지 미디어 옵션을 추가 할 수 있는 확장 가능한 코드가 포함되어 있습니다.
REST API

이전 회사에서 우리 팀은 서로 다른 엔드 포인트를 가진 수백 개의 API로 인한 골칫거리를 처리했습니다. 사람들은 HarperDB가 하나의 끝점에 불과하다는 것이 이상하다고 생각할 수 있지만 코드 본문을 살펴보면 모든 작업에 대해 변경해야 하는 것은 본문, 처음 몇 줄 뿐입니다. 이것은 매우 간단하며 REST 기반 애플리케이션을 작성할 때 매우 간단하게 만들 수 있습니다. 이것은 당신이 우리에게서 가져 와서 모든 응용 프로그램에서 사용할 수 있는 것입니다! 기본적으로 API에 단일 메시지를 게시하고 수행 중인 작업을 확인하고 표준 메서드 집합으로 처리합니다. 지난 몇 년 동안 많은 애플리케이션을 다시 작성했지만 이 부분은 거의 동일하게 유지되었습니다.
Management Studio
HarperDB Management Studio는 마이크로 서비스 위에 구축 된 React 프런트 엔드입니다 (그래서 우리는 개밥을 먹습니다). JavaScript의 한 가지 멋진 점은 사용 중인 프레임 워크 (Node, React 등)에 관계없이 얼마나 가벼우 며 이러한 다양한 레이어를 쉽게 결합 할 수 있다는 것입니다. React는 놀랍습니다. 프런트 엔드 개발의 품질을 바꾸고 애플리케이션에 더 쉽게 액세스 할 수 있게 해줍니다. 이를 기반으로 자체 API도 동시에 테스트하고 있으므로 매우 강력합니다. 제품 담당 부사장 인 Jaxon은 Studio를 위해 React를 선택했고 Stephen은 Express에서 백엔드 보고서를 작성했습니다.
AlaSQL
우리는 HarperDB의 백엔드 기능을 위해 AlaSQL을 선택했습니다. 여기에는 없는 훌륭한 기능이 포함되어 있으며 Math.js 및 GeoJSON과 같은 것을 연결할 수 있으므로 놀라운 패키지입니다. 이와 같은 언어로 Node를 사용하는 놀라운 이점 중 하나는 기술이 발전함에 따라 여러분이 원하고 필요한 대부분의 멋진 기능이 npm에 있다는 것입니다. 자체 SQL 파서를 구축해야 한다면 HarperDB를 구축하고 있을 것입니다. 경쟁사 인 FaunaDB가 출시되기까지 약 4 년이 걸렸지 만 6 개월 만에 제품 베타를 출시했고 12 개월 만에 원래 버전을 출시했으며 몇 달 전에 클라우드 제품을 출시했습니다 (약 3 년 후). 우리는 천재라고 말하는 것이 아니라 Node에서 개발함으로써 AlaSQL 개발자와 같은 사람들의 어깨에 서게 되었습니다. 이는 npm 커뮤니티에서 놀라운 사실을 발견했습니다.
Maths.js
Maths.js는 평균, 데이터 과학 등을 위한 또 다른 놀라운 패키지로, SQL 기능에 연결했습니다. 사용하기 어렵지 않고 AlaSQL과 함께 사용하면 매우 강력합니다.
Clustering/Replication

Node.js에서 무언가를 빌드 하는 또 다른 멋진 기능은 본질적으로 상태 비 저장이라는 것입니다. 즉, 세션 전반에 걸쳐 클라이언트를 제공하는 데 중요한 데이터를 메모리에 보관할 필요가 없으므로 매우 리소스 효율적입니다. 대부분의 엔터프라이즈 급 애플리케이션에는 매우 불안정해질 수 있는 백그라운드 프로세스와 상태 저장 변수가 있습니다. 노드는 상태 비 저장이며 웹용으로 설계되었으며 수평 적으로 확장하고 P2P가 되도록 설계되었습니다. Node 프레임 워크 사용의 놀라운 이점은 SocketCluster에 연결하여 클러스터링 및 복제를 지원할 수 있다는 것입니다.
HarperDB는 간단한 pub-sub 모델을 사용하므로 서로 다른 노드가 구독하고 수평으로 배포 할 수 있는 서로 다른 채팅방에 데이터를 게시하여 데이터를 복제합니다. 노드는 수평 적으로 확장 가능하고 다른 언어보다 리소스 집약적이지 않으며 상태 비 저장 특성으로 인해 매우 안정적입니다. 노드를 많은 컴퓨터에 배치 (수평 확장)하면 프레임 워크를 훨씬 더 강력하게 만들면서 비용을 절감하고 개발을 더 쉽게 하며 멋진 커뮤니티의 일원이 될 수 있습니다.
LMDB & File System
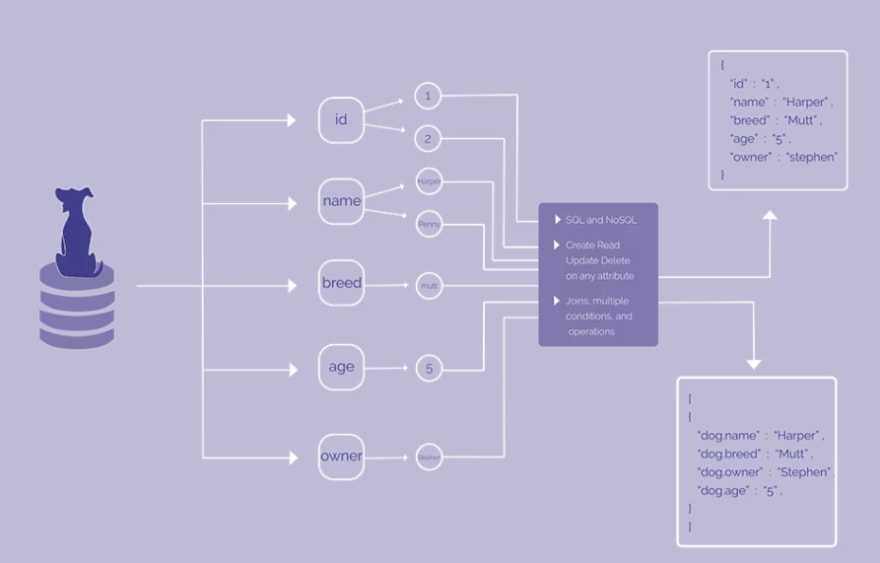
원래 우리는 위의 HarperDB 데이터 모델과 함께 직접 파일 시스템을 사용하고 있었는데 이것이 제품을 독특하게 만드는 이유입니다. 데이터가 들어 오면 SQL 엔진이나 NoSQL 엔진이 아닌 데이터 모델에 매핑 합니다. 해당 데이터를 개별 속성으로 분해하여 파일 시스템의 폴더 구조에 저장했습니다. 우리는 각각을 원자 적으로 저장하며 SQL 및 NoSQL을 통해 쿼리 할 수 있습니다. 규모에 따라 몇 가지 문제가 발생하여 최근에는 우리가 운영하는 핵심 가치 저장소 인 LMDB라는 패키지에 연결했습니다. 그 위에 정확한 데이터 모델을 구현할 수 있었으며 놀라운 성능 향상을 제공했습니다. 최근 벤치 마크에서 LMDB 덕분에 MongoDB보다 약 37 배 더 빨랐습니다.
등록된 댓글이 없습니다.