Javascript는 크게 개선되고 NodeJS라는 런타임 도입으로 인해 가장 널리 사용되고 널리 사용되는 언어 중 하나가 되었습니다.
웹이든 모바일 애플리케이션이든 Javascript는 이제 올바른 도구를 갖습니다.
이 기사에서는 NodeJS의 역동적인 생태계를 통해 웹을 효율적으로 긁어 대부분의 요구 사항을 충족시키는 방법을 설명합니다.
https://www.scrapingbee.com/blog/web-scraping-javascript/
전제 조건
이 글은 주로 자바 스크립트에 어느 정도의 경험이 있는 개발자를 대상으로 합니다. Web Scraping에 대해 잘 알고 있지만 Javascript에 대한 경험이 없는 경우 이 게시물이 여전히 유용 할 수 있습니다.
결과
이 게시물을 읽으면 다음을 수행 할 수 있습니다.
NodeJS 이해 : 간단한 소개
Javascript는 브라우저 내부의 웹 사이트에 동적 동작을 추가하기 위해 처음 작성된 단순하고 현대적인 언어입니다.
웹 사이트가 로드 되면 자바 스크립트는 브라우저의 자바 스크립트 엔진에 의해 실행되며 컴퓨터가 이해할 수 있는 많은 코드로 변환됩니다. Javascript가 브라우저와 상호 작용할 수 있도록 브라우저는 런타임 환경 (문서, 창 등)을 제공합니다.
이것은 자바스크립트가 컴퓨터 또는 리소스와 직접 상호 작용하거나 조작 할 수 있는 일종의 프로그래밍 언어가 아님을 의미합니다.
예를 들어, 웹 서버에서 서버는 파일 시스템과 상호 작용하여 파일을 읽거나 데이터베이스에 레코드를 저장할 수 있어야 합니다.
NodeJS를 도입하면서 아이디어의 핵심은 자바 스크립트가 클라이언트 측 뿐만 아니라 서버 측에서도 실행될 수 있게 하는 것이었습니다. 이를 가능하게 하기 위해 숙련 된 개발자인 Ryan Dahl은 문자 그대로 Chrome의 v8 Javascript Engine을 가져 와서 Node라는 C ++ 프로그램에 포함 시켰습니다. 따라서 NodeJS는 Javascript로 작성된 응용 프로그램이 서버에서도 실행될 수 있도록 하는 런타임 환경입니다.
C 또는 C ++와 같은 대부분의 언어가 다중 스레드를 사용하여 동시성을 처리하는 방식과 달리 NodeJS는 단일 기본 스레드를 사용하고 이를 사용하여 이벤트 루프를 통해 비 차단 방식으로 작업을 수행합니다.
간단한 웹 서버를 설치하는 것은 아래와 같이 매우 간단합니다.
const http = require('http');
const PORT = 3000;
const server = http.createServer((req, res) => {
res.statusCode = 200;
res.setHeader('Content-Type', 'text/plain');
res.end('Hello World');
});
server.listen(port, () => {
console.log(`Server running at PORT:${port}/`);
});NodeJS가 설치되어 있고 node <YourFileNameHere>.js <및>를 입력하지 않고 위 코드를 실행하고 브라우저를 열고 localhost : 3000으로 이동하면“Hello World”라는 텍스트가 표시됩니다. NodeJS는 I/O 집약적인 애플리케이션에 매우 이상적입니다.
HTTP 클라이언트 : 웹 쿼리
HTTP 클라이언트는 서버로 요청을 보낸 후 응답을 받을 수 있는 도구입니다. 논의 할 거의 모든 도구는 웹 클라이언트를 긁어 모으려는 웹 서버를 쿼리 하기 위해 HTTP 클라이언트를 사용합니다.
Request
Request는 Javascript 에코 시스템에서 가장 널리 사용되는 HTTP 클라이언트 중 하나이지만 현재 Request 라이브러리 작성자는 더 이상 사용되지 않는다고 공식적으로 선언했습니다. 이것은 사용할 수 없다는 것을 의미하지는 않지만, 여전히 많은 라이브러리가 사용하고 있으며 사용할 가치가 있습니다. Request를 사용하여 HTTP 요청을 만드는 것은 매우 간단합니다.
const request = require('request')
request('https://www.reddit.com/r/programming.json', function (
error,
response,
body
) {
console.error('error:', error)
console.log('body:', body)
})Github에서 요청 라이브러리를 찾을 수 있으며 설치는 npm 설치 요청을 실행하는 것만 큼 간단합니다. 또한 지원 중단 통지와 이것이 의미하는 바를 찾을 수 있습니다. 이 라이브러리가 더 이상 사용되지 않는다는 사실에 대해 안전하지 않다면 아래에 더 많은 것이 있습니다!
Axios
Axios는 브라우저와 NodeJS에서 모두 실행되는 약속 기반 HTTP 클라이언트입니다. Typescript를 사용하는 경우 axios는 내장 유형으로 덮여 있습니다. Axios로 HTTP 요청을 하는 것은 간단합니다. 요청에서 콜백을 사용하는 대신 기본적으로 약속 한 지원이 제공됩니다.
const axios = require('axios')
axios
.get('https://www.reddit.com/r/programming.json')
.then((response) => {
console.log(response)
})
.catch((error) => {
console.error(error)
});Promises API에 대해 async / await 구문 설탕을 상상한다면, 그렇게 할 수 있지만 최상위 await는 여전히 3 단계이므로 Async 함수를 대신 사용해야 합니다.
async function getForum() {
try {
const response = await axios.get(
'https://www.reddit.com/r/programming.json'
)
console.log(response)
} catch (error) {
console.error(error)
}
}getForum에 전화하면 됩니다. Github에서 Axios 라이브러리를 찾을 수 있으며 Axios 설치는 npm install axios만큼 간단합니다.
Superagent
Axios와 마찬가지로 Superagent는 약속 및 비동기 / 대기 구문 설탕을 지원하는 또 다른 강력한 HTTP 클라이언트입니다. Axios와 같이 매우 간단한 API를 가지고 있지만 Superagent는 더 많은 의존성을 가지고 덜 인기가 있습니다.
어쨌든 약속, async / await 또는 콜백을 사용하여 Superagent로 HTTP 요청을 하는 것은 다음과 같습니다.
const superagent = require("superagent")
const forumURL = "https://www.reddit.com/r/programming.json"
// callbacks
superagent
.get(forumURL)
.end((error, response) => {
console.log(response)
})
// promises
superagent
.get(forumURL)
.then((response) => {
console.log(response)
})
.catch((error) => {
console.error(error)
})
// promises with async/await
async function getForum() {
try {
const response = await superagent.get(forumURL)
console.log(response)
} catch (error) {
console.error(error)
}
}Github에서 Superagent 라이브러리를 찾을 수 있으며 Superagent 설치는 npm install superagent만큼 간단합니다.
다가오는 웹 스크래핑 도구의 경우 Axios가 HTTP 클라이언트로 사용됩니다.
정규식 : 어려운 방법
의존성 없이 웹 스크래핑을 시작하는 가장 간단한 방법은 HTTP 클라이언트를 사용하여 웹 페이지를 쿼리하여 수신하는 HTML 문자열에 많은 정규식을 사용하는 것이지만 큰 절충점이 있습니다.
정규 표현식은 유연하지 않으며 전문가와 아마추어 모두 올바른 정규 표현식을 작성하는 데 어려움을 겪고 있습니다.
복잡한 웹 스크래핑의 경우 정규식도 매우 빨리 벗어날 수 있습니다. 그 말로, 가자. 사용자 이름이 포함 된 레이블이 있다고 가정 해 보겠습니다.
사용자 이름이 필요합니다. 이는 정규식에 의존하는 경우 수행해야 하는 것과 유사합니다.
const htmlString = '<label>Username: John Doe</label>'
const result = htmlString.match(/<label>(.+)<\/label>/)
console.log(result[1], result[1].split(": ")[1])
// Username: John Doe, John DoeJavascript에서 match()는 일반적으로 정규식과 일치하는 모든 항목이 포함 된 배열을 반환합니다. 두 번째 요소 (인덱스 1)에는 <label> 태그의 textContent 또는 innerHTML이 있습니다. 그러나 이 결과에는 제거해야 하는 원치 않는 텍스트 ( "사용자 이름 :")가 포함되어 있습니다.
보시다시피, 매우 간단한 유스 케이스의 경우, 수행해야 할 단계와 작업이 불필요하게 높습니다. 이것이 바로 다음에 설명 할 HTML 파서와 같은 것에 의존해야 하는 이유입니다.
Cheerio : DOM 탐색을 위한 핵심 JQuery
Cheerio는 서버 측에서 풍부하고 강력한 JQuery API를 사용할 수있는 효율적이고 가벼운 라이브러리입니다. 이전에 JQuery를 사용한 적이 있다면 Cheerio를 사용하여 집에서 바로 느낄 수 있습니다. 모든 DOM 불일치 및 브라우저 관련 기능을 제거하고 DOM을 구문 분석하고 조작하는 효율적인 API를 제공합니다.
const cheerio = require('cheerio')
const $ = cheerio.load('<h2 class="title">Hello world</h2>')
$('h2.title').text('Hello there!')
$('h2').addClass('welcome')
$.html()
// <h2 class="title welcome">Hello there!</h2>보다시피 Cheerio를 사용하는 것은 JQuery를 사용하는 방법과 매우 유사합니다.
그러나 웹 브라우저와 동일한 방식으로 작동하지는 않지만 다음과 같이 작동하지 않습니다.
따라서 크롤링 하려는 웹 사이트 또는 웹 응용 프로그램이 Javascript를 많이 사용하는 경우 (예 : 단일 페이지 응용 프로그램) Cheerio가 최선의 방법이 아닌 경우 나중에 설명 할 다른 옵션 중 일부에 의존해야 할 수 있습니다.
Cheerio의 힘을 보여주기 위해 Reddit에서 r / 프로그래밍 포럼을 크롤링하고 게시물 이름 목록을 가져 오려고 합니다.
먼저 다음 명령을 실행하여 Cheerio 및 axios를 설치하십시오. npm install cheerio axios.
그런 다음 crawler.js라는 새 파일을 만들고 다음 코드를 복사 / 붙여 넣기 하십시오.
const axios = require('axios');
const cheerio = require('cheerio');
const getPostTitles = async () => {
try {
const { data } = await axios.get(
'https://old.reddit.com/r/programming/'
);
const $ = cheerio.load(data);
const postTitles = [];
$('div > p.title > a').each((_idx, el) => {
const postTitle = $(el).text()
postTitles.push(postTitle)
});
return postTitles;
} catch (error) {
throw error;
}
};
getPostTitles()
.then((postTitles) => console.log(postTitles));getPostTitles()는 오래된 reddit의 r / programming forum을 크롤링 하는 비동기 함수입니다. 먼저 웹 사이트의 HTML은 axios HTTP 클라이언트 라이브러리와 함께 간단한 HTTP GET 요청을 사용하여 얻은 다음 cheerio.load () 함수를 사용하여 html 데이터가 Cheerio에 제공됩니다.
그런 다음 브라우저의 개발 도구를 사용하여 일반적으로 모든 엽서를 대상으로 할 수 있는 선택기를 얻을 수 있습니다. JQuery를 사용한 경우 $( 'div> p.title> a')는 매우 친숙해야 합니다. 각 게시물의 제목 만 개별적으로 원하기 때문에 모든 게시물을 가져옵니다. 각 게시물을 반복해야 합니다. 각 게시물은 each () 함수의 도움으로 수행됩니다.
각 타이틀에서 텍스트를 추출하려면 Cheerio의 도움으로 DOM 요소를 가져와야 합니다 (el은 현재 요소를 나타냄). 그런 다음 각 요소에서 text()를 호출하면 텍스트가 제공됩니다.
이제 터미널을 열고 노드 crawler.js를 실행하면 약 25 개 또는 26 개의 서로 다른 게시물 제목이 표시됩니다. 이것은 매우 간단한 사용 사례이지만 Cheerio가 제공하는 API의 간단한 특성을 보여줍니다.
사용 사례에 Javascript 실행 및 외부 소스 로드가 필요한 경우 다음 몇 가지 옵션이 도움이 됩니다.
JSDOM : 노드의 DOM
JSDOM은 NodeJS에서 사용되는 Document Object Model의 순수 Javascript 구현입니다. 앞에서 언급 한 바와 같이 DOM은 Node에서 사용할 수 없으므로 JSDOM이 가장 근접합니다. 브라우저를 거의 모방하지 않습니다.
DOM이 생성되므로 프로그래밍 방식으로 크롤링 하려는 웹 응용 프로그램 또는 웹 사이트와 상호 작용할 수 있으므로 버튼 클릭과 같은 것이 가능합니다. DOM 조작에 익숙하다면 JSDOM을 사용하는 것이 매우 간단합니다.
const { JSDOM } = require('jsdom')
const { document } = new JSDOM(
'<h2 class="title">Hello world</h2>'
).window
const heading = document.querySelector('.title')
heading.textContent = 'Hello there!'
heading.classList.add('welcome')
heading.innerHTML
// <h2 class="title welcome">Hello there!</h2>보시다시피 JSDOM은 DOM을 작성한 다음 브라우저 DOM을 조작 할 때 사용하는 것과 동일한 메소드 및 특성으로 이 DOM을 조작 할 수 있습니다.
JSDOM을 사용하여 웹 사이트와 상호 작용하는 방법을 보여주기 위해 Reddit r / programming 포럼의 첫 번째 게시물을 가져 와서 투표 한 다음 게시물이 공개되었는지 확인합니다.
다음 명령을 실행하여 jsdom 및 axios를 설치하십시오. npm install jsdom axios
그런 다음 crawler.js라는 이름으로 파일을 만들고 다음 코드를 복사 / 붙여 넣기 하십시오.
const { JSDOM } = require("jsdom")
const axios = require('axios')
const upvoteFirstPost = async () => {
try {
const { data } = await axios.get("https://old.reddit.com/r/programming/");
const dom = new JSDOM(data, {
runScripts: "dangerously",
resources: "usable"
});
const { document } = dom.window;
const firstPost = document.querySelector("div > div.midcol > div.arrow");
firstPost.click();
const isUpvoted = firstPost.classList.contains("upmod");
const msg = isUpvoted
? "Post has been upvoted successfully!"
: "The post has not been upvoted!";
return msg;
} catch (error) {
throw error;
}
};
upvoteFirstPost().then(msg => console.log(msg));upvoteFirstPost()는 r / programming에서 첫 번째 게시물을 얻은 다음 upvote하는 비동기 함수입니다. 이를 위해 axios는 지정된 URL의 HTML을 가져 오기 위해 HTTP GET 요청을 보냅니다. 그런 다음 이전에 가져온 HTML을 제공하여 새 DOM이 작성됩니다.
JSDOM 생성자는 HTML을 첫 번째 인수로 사용하고 옵션을 두 번째 인수로 사용하며 추가 된 2 개의 옵션은 다음 기능을 수행합니다.
DOM이 작성되면 동일한 DOM 메소드를 사용하여 첫 번째 게시물의 upvote 버튼을 가져온 다음 클릭하십시오. 실제로 클릭 되었는지 확인하기 위해 upmod라는 클래스의 classList를 확인할 수 있습니다. 이 클래스가 classList에 있으면 메시지가 리턴됩니다.
이제 터미널을 열고 노드 crawler.js를 실행하면 게시물이 올라 왔는지 여부를 알려주는 깔끔한 문자열이 표시됩니다. 이 사용 사례는 사소한 것이지만,이를 기반으로 특정 사용자의 게시물을 올리는 봇과 같은 강력한 무언가를 만들 수 있습니다.
JSDOM의 표현력 부족을 싫어하고 크롤링이 이러한 많은 조작에 크게 의존하거나 많은 다른 DOM을 다시 작성해야 하는 경우 다음 옵션이 더 적합합니다.
Puppeteer: The headless browser
Puppeteer는 이름에서 알 수 있듯이 꼭두각시가 꼭두각시를 조작하는 방식과 마찬가지로 프로그래밍 방식으로 브라우저를 조작 할 수 있습니다. 기본적으로 헤드리스 버전의 Chrome을 제어 할 수 있는 고급 API를 개발자에게 제공하여 헤드리스 없이 실행되도록 구성 할 수 있습니다.
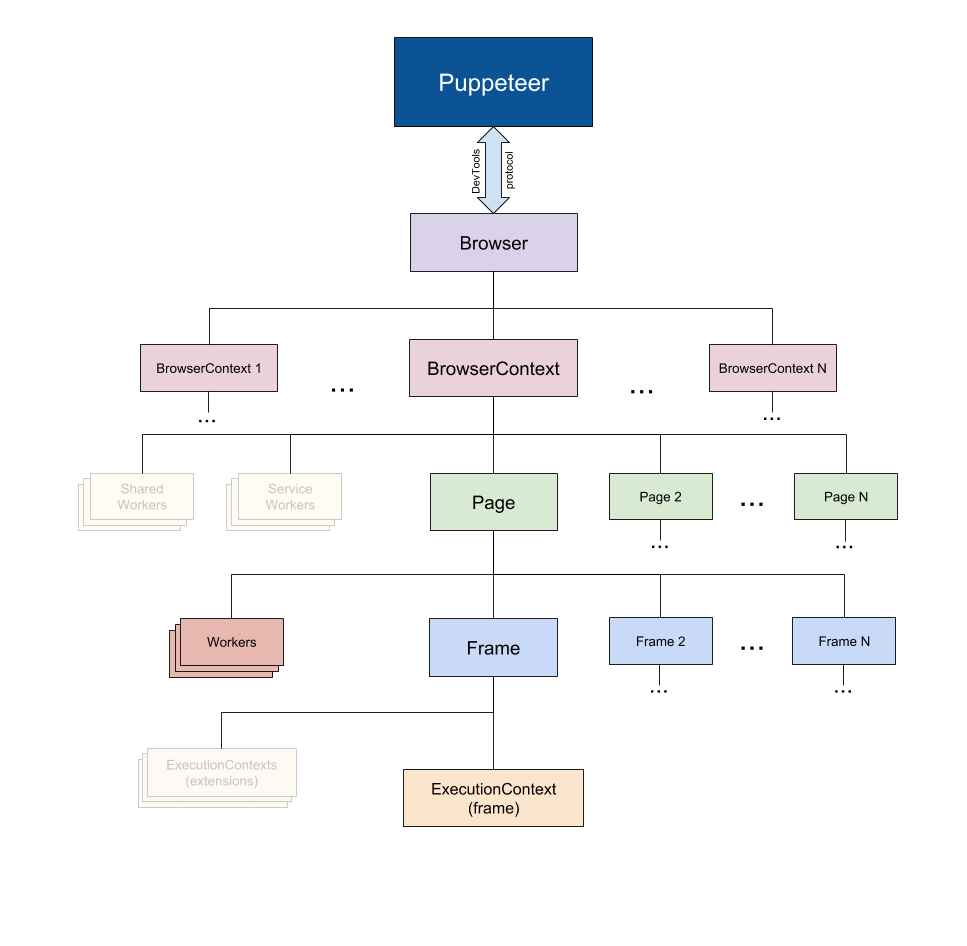 Puppeter Docs (출처)에서 발췌
Puppeter Docs (출처)에서 발췌
Puppeteer는 실제 사람이 브라우저와 상호 작용하는 것처럼 웹을 크롤링 할 수 있기 때문에 위에서 언급 한 도구보다 특히 유용합니다. 이것은 전에 없었던 몇 가지 가능성을 열어줍니다.
또한 UI 테스트, 성능 최적화 지원 등과 같은 웹 크롤링 범위를 벗어난 다른 많은 작업에서 큰 역할을 할 수 있습니다.
웹 사이트의 스크린 샷을 찍고 경쟁 업체의 제품 카탈로그에 대해 알고 싶을 때 종종 인형을 사용하여 이를 수행 할 수 있습니다. 시작하려면 puppeteer를 설치해야 합니다. 이렇게 하려면 다음 명령을 실행하십시오. npm install puppeteer
운영 체제에 따라 번들로 제공되는 Chromium 버전이 약 180MB에서 300MB까지 다운로드 됩니다. 이 기능을 비활성화하고 인형을 이미 다운로드 한 크롬 버전으로 지정하려면 몇 가지 환경 변수를 설정해야 합니다. 그러나 이 자습서에서 Chromium 및 puppeteer를 다운로드하지 않으려면 꼭 puppeteer 운동장을 이용하십시오.
Reddit에서 r / 프로그래밍 포럼의 스크린 샷과 PDF를 가져와 crawler.js라는 새 파일을 만든 후 다음 코드를 복사 / 붙여 넣기 해 보겠습니다.
const puppeteer = require('puppeteer')
async function getVisual() {
try {
const URL = 'https://www.reddit.com/r/programming/'
const browser = await puppeteer.launch()
const page = await browser.newPage()
await page.goto(URL)
await page.screenshot({ path: 'screenshot.png' })
await page.pdf({ path: 'page.pdf' })
await browser.close()
} catch (error) {
console.error(error)
}
}
getVisual()getVisual()은 URL 변수에 지정된 값의 스크린 샷과 pdf를 가져 오는 비동기 함수입니다. 시작하려면 puppeteer.launch()를 실행하여 브라우저 인스턴스를 만든 다음 새 페이지를 만듭니다. 이 페이지는 일반 브라우저의 탭처럼 생각할 수 있습니다. 그런 다음 URL을 매개 변수로 사용하여 page.goto()를 호출하면 이전에 작성된 페이지가 지정된 URL로 이동합니다. 마지막으로 브라우저 인스턴스가 페이지와 함께 파괴됩니다.
이 작업이 완료되고 페이지 로드가 완료되면 page.screenshot() 및 page.pdf()를 각각 사용하여 스크린 샷과 pdf가 생성됩니다. 자바 스크립트 로드 이벤트를 수신 한 후 이러한 조치도 수행 할 수 있으므로 프로덕션 레벨에서 권장됩니다.
crawler.js 노드의 코드 유형을 터미널로 실행하고 몇 초 후에 screenshot.jpg 및 page.pdf라는 이름의 파일 2 개가 생성되었음을 알 수 있습니다.
Nightmare: An alternative to Puppeteer
Nightmare는 Puppeteer와 같은 고급 브라우저 자동화 라이브러리로 Electron을 사용하지만 이전 버전 인 PhantomJS보다 훨씬 두 배 빠르며 최신 버전입니다.
Puppeteer를 어떤 식으로든 싫어하거나 Chromium 번들의 크기에 실망한 경우 Nightmare가 이상적인 선택입니다. 시작하려면 다음 명령을 실행하여 installghtmare 라이브러리를 설치하십시오. npm install nightmare
그런 다음 악몽이 다운로드 되면 이를 사용하여 Google 검색 엔진을 통해 ScrapingBee의 웹 사이트를 찾습니다. 이렇게 하려면 crawler.js라는 파일을 만든 후 다음 코드를 복사하여 붙여 넣습니다.
const Nightmare = require('nightmare')
const nightmare = Nightmare()
nightmare
.goto('https://www.google.com/')
.type("input[title='Search']", 'ScrapingBee')
.click("input[value='Google Search']")
.wait('#rso > div:nth-child(1) > div > div > div.r > a')
.evaluate(
() =>
document.querySelector(
'#rso > div:nth-child(1) > div > div > div.r > a'
).href
)
.end()
.then((link) => {
console.log('Scraping Bee Web Link': link)
})
.catch((error) => {
console.error('Search failed:', error)
})먼저 Nighmare 인스턴스가 생성되면 이 인스턴스는 일단로드되면 goto()를 호출하여 Google 검색 엔진으로 전송되고 선택기를 사용하여 검색 상자를 가져온 다음 검색 상자의 값 (입력 태그)이 변경됩니다. "ScrapingBee"에. 완료되면 "Google 검색"버튼을 클릭하여 검색 양식을 제출하십시오. 그런 다음 Nightmare는 첫 번째 링크가 로드 될 때까지 기다렸다가 DOM 링크를 사용하여 링크가 포함 된 앵커 태그의 href 속성 값을 가져옵니다.
마지막으로 모든 것이 완료되면 링크가 콘솔에 인쇄됩니다. 코드를 실행하려면 node crawler.js를 터미널에 입력하십시오.
요약
오래 읽었습니다! 그러나 이제 NodeJS를 사용하는 다양한 방법을 이해하고 원하는 방식으로 웹을 크롤링하는 풍부한 라이브러리 에코 시스템을 이해합니다. 마무리하기 위해, 당신은 배웠습니다 :
NodeJS는 서버 측에서 Javascript를 실행할 수있는 Javascript 런타임입니다. 이벤트 루프 덕분에 비 차단 특성을 갖습니다.
Axios, Superagent 및 Request와 같은 HTTP 클라이언트는 HTTP 요청을 서버로 보내고 응답을 받는 데 사용됩니다.
Cheerio는 웹 크롤링을 위해 서버 측에서 실행하기 위한 목적으로 만 JQuery를 최대한 활용하지만 Javascript 코드는 실행하지 않습니다.
JSDOM은 HTML 문자열에서 표준 Javascript 스펙에 따라 DOM을 작성하고 DOM 조작을 수행 할 수 있게 합니다.
Puppeteer와 Nightmare는 고급 브라우저 자동화 라이브러리로, 마치 실제 사람이 상호 작용하는 것처럼 웹 응용 프로그램을 프로그래밍 방식으로 조작 할 수 있습니다.
자원
등록된 댓글이 없습니다.