완전한 HTML 사이트를 긁어내는 필수 Python 도구를 사용하여 실습 경험을 쌓으십시오.
파이썬을 배우는 데 도움이 되는 훌륭한 책이 많이 있지만 실제로 누가 A부터 Z까지 읽습니까? (스포일러 : 나 아님).
https://opensource.com/article/20/5/web-scraping-python
많은 사람들이 교과서를 유용하게 생각하지만, 나는 책을 앞뒤로 읽음으로써 배우지 않습니다.
나는 프로젝트를 하고, 고군분투하고, 무언가를 알아 낸 다음, 다른 책을 읽음으로써 배웁니다.
자, 이제 책을 버리고 파이썬을 배우자.
다음은 Python에서 첫 번째 스크래핑 프로젝트에 대한 가이드입니다.
파이썬과 HTML에 대한 가정 지식이 매우 낮습니다. 이것은 Python 라이브러리 요청으로 웹 페이지 컨텐츠에 액세스하고 JSON 및 팬더뿐만 아니라 BeatifulSoup4를 사용하여 컨텐츠를 구문 분석하는 방법을 설명하기 위한 것입니다.
저는 Selenium을 간략하게 소개하지만, 그 라이브러리를 사용하는 방법에 대해서는 자세히 다루지 않겠습니다.
궁극적으로 웹 스크래핑을 덜 압도적으로 만드는 몇 가지 요령과 팁을 보여 드리고자 합니다.
의존성 설치
이 안내서의 모든 자료는 GitHub 리포지토리에 있습니다. Python 3 설치에 도움이 필요하면 Linux, Windows 및 Mac에 대한 자습서를 확인하십시오.
$ python3 -m venv
$ source venv/bin/activate
$ pip install requests bs4 pandas
JupyterLab을 사용하고 싶다면 이 노트북을 사용하여 모든 코드를 실행할 수 있습니다. JupyterLab을 설치하는 방법은 여러 가지가 있으며 다음 중 하나입니다.
# from the same virtual environment as above, run:
$ pip install jupyterlab
웹 스크래핑 프로젝트의 목표 설정
이제 의존성을 설치했지만 웹 페이지를 긁어내는 데 무엇이 필요합니까?
한 걸음 물러서서 우리의 목표를 분명히 하자. 다음은 성공적인 웹 스크래핑 프로젝트를 위한 요구 사항 목록입니다.
HTML에 대한 의견 : HTML은 인터넷을 운영하는 짐승이지만 대부분 이해해야 할 것은 태그의 작동 방식입니다.
태그는 꺾쇠 괄호로 묶인 레이블 사이에 삽입 된 정보 모음입니다. 예를 들어, 다음은 "pro-tip"이라는 척 태그입니다.
<pro-tip> All you need to know about html is how tags work </pro-tip>
"pro-tip"태그를 호출하여 그 안에 있는 정보 ( "알아야 할 모든 것…")에 액세스 할 수 있습니다. 태그를 찾고 액세스하는 방법은 이 튜토리얼에서 자세히 다룰 것입니다. HTML 기본 사항에 대한 자세한 내용은 이 기사를 확인하십시오.
웹 스크래핑 프로젝트에서 찾아야 할 것
데이터 수집에 대한 일부 목표는 다른 목표보다 웹 스크래핑에 더 적합합니다. 좋은 프로젝트 자격을 갖추기 위한 지침은 다음과 같습니다.
데이터에 사용할 수 있는 공개 API가 없습니다. API를 통해 구조화 된 데이터를 캡처 하는 것이 훨씬 쉬울 것이며 데이터 수집의 적법성과 윤리를 명확히 하는 데 도움이 될 것입니다.
이러한 노력을 정당화하려면 규칙적이고 반복 가능한 형식으로 상당한 양의 구조화 된 데이터가 필요합니다.
웹 스크래핑은 어려울 수 있습니다. BeautifulSoup (bs4)을 사용하면 이 작업을 보다 쉽게 수행 할 수 있지만 사용자 지정이 필요한 웹 사이트의 개별 특성을 피할 수는 없습니다.
동일한 형식의 데이터는 필요하지 않지만 작업이 더 쉬워집니다. "가장 높은 경우"(표준에서 출발)가 많을수록 스크래핑이 더 복잡해집니다.
면책 조항 : 저는 법적 교육이 없습니다. 다음은 공식적인 법률 자문이 아닙니다.
합법성에 관해, 방대한 정보에 접근하는 것은 술에 취할 수 있지만 그것이 가능하다고 해서 반드시 그렇게 해야 한다는 것을 의미하지는 않습니다.
고맙게도 우리의 도덕과 웹 스크레이퍼를 안내 할 수 있는 공개 정보가 있습니다. 대부분의 웹 사이트에는 사이트와 관련된 robots.txt 파일이 있으며, 이는 어떤 스크래핑 활동이 허용되고 허용되지 않는지를 나타냅니다. 검색 엔진 (최고의 웹 스크레이퍼)과 상호 작용하기 위해 주로 있습니다. 그러나 웹 사이트의 많은 정보는 공개 정보로 간주됩니다. 따라서 일부는 robots.txt 파일을 법적 구속력이 있는 문서가 아닌 일련의 권장 사항으로 간주합니다. robots.txt 파일은 윤리적 수집 및 데이터 사용과 같은 주제를 다루지 않습니다.
스크래핑 프로젝트를 시작하기 전에 나 자신에게 묻는 질문 :
사이트를 긁을 때 모든 질문에 "아니오"로 답할 수 있는지 확인합니다.
법적 문제에 대한 자세한 내용은 2018 년 간행물 Krotov와 Silva의 웹 스크랩 핑의 합법성과 윤리 및 20 년간의 웹 스크랩 핑과 Sellars의 컴퓨터 사기 및 남용 행위를 참조하십시오.
이제 긁을 시간이다!
위의 내용을 평가 한 후 프로젝트를 생각해 냈습니다. 저의 목표는 아이다 호의 모든 Family Dollar 매장 주소를 추출하는 것이었습니다. 이 상점들은 시골 지역에 비해 규모가 크므로 시골 지역에 얼마나 많은지 알고 싶습니다.
시작점은 Family Dollar의 위치 페이지입니다.
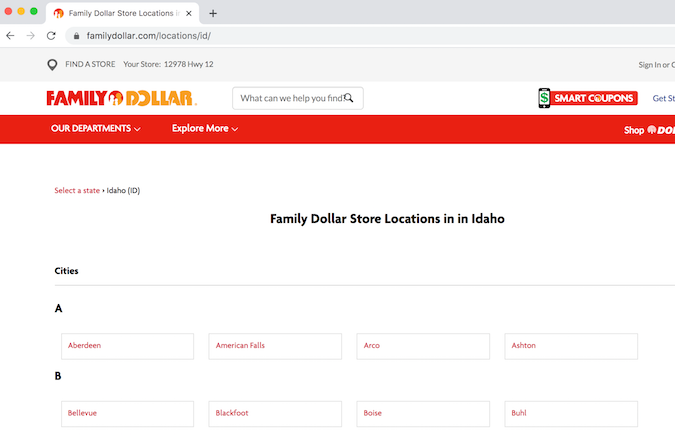
먼저 파이썬 가상 환경에 전제 조건을 로드 해 봅시다. 여기의 코드는 Python 파일 (이름을 찾는 경우 scraper.py)에 추가되거나 JupyterLab의 셀에서 실행됩니다.
import requests # for making standard html requests
from bs4 import BeautifulSoup # magical tool for parsing html data
import json # for parsing data
from pandas import DataFrame as df # premier library for data organization
다음으로 타겟 URL에 데이터를 요청합니다.
page = requests.get("https://locations.familydollar.com/id/")
soup = BeautifulSoup(page.text, 'html.parser')
BeautifulSoup은 HTML 또는 XML 컨텐츠를 가져 와서 복잡한 객체 트리로 변환합니다. 사용할 몇 가지 일반적인 객체 유형은 다음과 같습니다.
requests.get () 출력을 볼 때 고려해야 할 사항이 더 있습니다. 요청 된 페이지를 읽을 수 있는 것으로 변환하기 위해 page.text () 만 사용했지만 다른 출력 유형이 있습니다.
나는 라틴 알파벳을 사용하는 영어 전용 사이트에서만 일했습니다. 요청의 기본 인코딩 설정이 제대로 작동했습니다.
그러나 영어 전용 사이트를 넘어 풍부한 인터넷 세상이 있습니다.
요청이 컨텐츠를 올바르게 구문 분석하도록 하기 위해 텍스트 인코딩을 설정할 수 있습니다.
page = requests.get(URL)
page.encoding = 'ISO-885901'
soup = BeautifulSoup(page.text, 'html.parser')
BeautifulSoup 태그를 자세히 살펴보면 다음과 같습니다.
관련 컨텐츠를 추출하는 방법 결정
경고 :이 프로세스는 실망스러울 수 있습니다.
웹 스크래핑 중 추출은 잘못된 단계로 가득 찬 어려운 과정이 될 수 있습니다.
나는 이것에 접근하는 가장 좋은 방법은 하나의 대표적인 예제로 시작한 다음 확장하는 것입니다 (이 원칙은 모든 프로그래밍 작업에 해당됩니다). 페이지의 HTML 소스 코드를 보는 것이 필수적입니다.
이를 수행하는 방법에는 여러 가지가 있습니다.
터미널에서 Python을 사용하여 페이지의 전체 소스 코드를 볼 수 있습니다 (권장되지 않음). 이 코드는 귀하의 책임하에 실행하십시오 :
print(soup.prettify())
페이지의 전체 소스 코드를 인쇄하면 일부 자습서에 표시된 장난감 예제에서 작동 할 수 있지만 대부분의 최신 웹 사이트에는 해당 페이지 중 하나에 많은 양의 콘텐츠가 있습니다. 404 페이지조차도 머리글, 바닥 글 등의 코드로 채워질 수 있습니다.
즐겨 찾는 브라우저에서 페이지 소스보기를 통해 소스 코드를 찾아 보는 것이 가장 쉬운 방법입니다 (마우스 오른쪽 버튼을 클릭 한 후 "페이지 소스보기"를 선택하십시오).
이것이 타겟 콘텐츠를 찾는 가장 신뢰할 수 있는 방법입니다 (이유는 잠시 후에 설명하겠습니다).

이 경우 이 광대 한 HTML 오션에서 대상 컨텐츠 (주소, 도시, 주 및 우편 번호)를 찾아야 합니다. 종종 페이지 소스 (ctrl + F)를 검색하면 타겟 위치가 있는 섹션이 생성됩니다.
대상 컨텐츠 (최소 한 상점의 주소)의 예를 실제로 볼 수 있게 되면 이 컨텐츠를 나머지 컨텐츠와 구분하는 속성 또는 태그를 찾습니다.
먼저, Family Dollar 매장과 함께 아이다 호의 여러 도시에 대한 웹 주소를 수집하고 해당 웹 사이트를 방문하여 주소 정보를 가져와야 합니다. 이 웹 주소는 모두 href 태그로 묶인 것으로 보입니다. 큰! find_all 명령을 사용하여 검색을 시도합니다.
dollar_tree_list = soup.find_all('href')
dollar_tree_list
href를 검색해도 아무런 결과가 없었습니다. href가 클래스 항목 목록 안에 중첩되어 있기 때문에 실패했을 수 있습니다. 다음 시도는 item_list를 검색하십시오. "class"는 파이썬에서 예약어이므로 class_가 대신 사용됩니다. bs4 함수 soup.find_all()은 bs4 함수의 스위스 군용 칼로 판명되었습니다.
dollar_tree_list = soup.find_all(class_ = 'itemlist')
for i in dollar_tree_list[:2]:
print(i)
일화적으로 특정 클래스를 검색하는 것이 종종 성공적인 접근 방법이라는 것을 알았습니다. 객체의 유형과 길이를 찾아서 객체에 대해 더 배울 수 있습니다.
type(dollar_tree_list)
len(dollar_tree_list)
이 BeautifulSoup "ResultSet"의 컨텐츠는 .contents를 사용하여 추출 할 수 있습니다. 또한 단일 대표 예제를 작성하기에 좋은시기 입니다.
example = dollar_tree_list[2] # a representative example
example_content = example.contents
print(example_content)
.attr을 사용하여 이 객체의 내용에 어떤 속성이 있는지 찾으십시오. 참고 : .contents는 일반적으로 정확히 하나의 항목 목록을 반환하므로 첫 번째 단계는 대괄호 표기법을 사용하여 해당 항목을 색인화 하는 것입니다.
example_content = example.contents[0]
example_content.attrs
href가 사전 항목처럼 추출 될 수 있는 속성임을 알 수 있습니다.
example_href = example_content['href']
print(example_href)
웹 스크레이퍼 정리
그 모든 탐험은 우리에게 앞으로 나아갈 길을 제공했습니다. 우리가 위에서 알아 낸 정리 된 버전은 다음과 같습니다.
city_hrefs = [] # initialise empty list
for i in dollar_tree_list:
cont = i.contents[0]
href = cont['href']
city_hrefs.append(href)
# check to be sure all went well
for i in city_hrefs[:2]:
print(i)
출력은 아이다 호에 있는 Family Dollar 상점의 URL 목록을 긁습니다.
즉, 여전히 주소 정보가 없습니다! 이제 이 정보를 얻으려면 각 도시 URL을 스크랩해야 합니다. 따라서 하나의 대표적인 예를 사용하여 프로세스를 다시 시작합니다.
page2 = requests.get(city_hrefs[2]) # again establish a representative example
soup2 = BeautifulSoup(page2.text, 'html.parser')
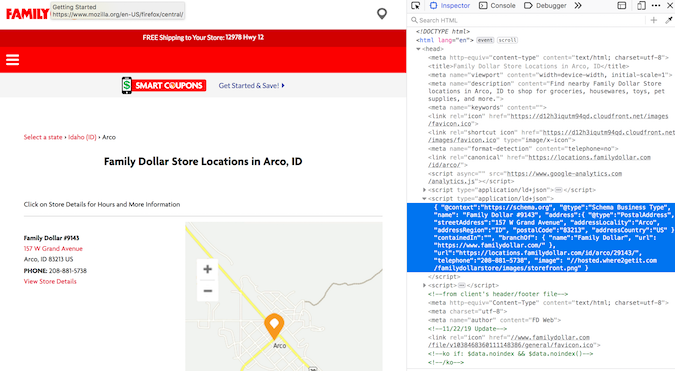
주소 정보는 type = "application / ld + json"내에 중첩됩니다. 많은 지리적 위치 스크래핑을 수행 한 후 이를 주소 정보를 저장하는 일반적인 구조로 인식하게되었습니다. 다행히, soup.find_all ()은 타입 검색도 가능합니다.
arco = soup2.find_all(type="application/ld+json")
print(arco[1])
주소 정보는 두 번째 목록 회원입니다! 드디어!
.contents를 사용하여 내용 (두 번째 목록 항목에서)을 추출했습니다 (수프를 필터링 한 후 좋은 기본 동작입니다).
다시 한 번 내용의 출력이 하나의 목록이므로 해당 목록 항목을 색인화 했습니다.
arco = soup2.find_all(type="application/ld+json")
print(arco[1])
주소 정보는 두 번째 목록 회원입니다! 드디어!
.contents를 사용하여 내용 (두 번째 목록 항목에서)을 추출했습니다 (수프를 필터링 한 후 좋은 기본 동작입니다). 다시 한 번 내용의 출력이 하나의 목록이므로 해당 목록 항목을 색인화 했습니다.
arco_contents = arco[1].contents[0]
arco_contents
여기에 제시된 형식은 JSON 형식과 일치합니다 (또한 형식에 이름에 "json"이 있음). JSON 객체는 내부에 중첩 된 사전이 있는 사전처럼 작동 할 수 있습니다. 실제로 익숙해지면 작업하기에 좋은 형식입니다. 긴 일련의 RegEx 명령보다 프로그래밍이 훨씬 쉽습니다. 이것은 구조적으로 JSON 객체처럼 보이지만 여전히 bs4 객체이며 JSON으로 액세스하려면 JSON으로 프로그래밍 방식으로 공식적으로 변환해야 합니다.
arco_json = json.loads(arco_contents)
type(arco_json)
print(arco_json)
그 내용에는 작은 중첩 된 사전에 원하는 주소 정보가 있는 address라는 키가 있습니다. 따라서 다음과 같이 검색 할 수 있습니다.
arco_address = arco_json['address']
arco_address
좋아, 이번엔 진지해 이제 아이다 호에서 목록 저장소 URL을 반복 할 수 있습니다.
locs_dict = [] # initialise empty list
for link in city_hrefs:
locpage = requests.get(link) # request page info
locsoup = BeautifulSoup(locpage.text, 'html.parser')
# parse the page's content
locinfo = locsoup.find_all(type="application/ld+json")
# extract specific element
loccont = locinfo[1].contents[0]
# get contents from the bs4 element set
locjson = json.loads(loccont) # convert to json
locaddr = locjson['address'] # get address
locs_dict.append(locaddr) # add address to list
팬더로 웹 스크래핑 결과 정리
우리는 사전에 많은 양의 데이터를 가지고 있지만, 데이터 재사용이 필요한 것보다 더 복잡하게 만드는 몇 가지 추가 지침이 있습니다.
최종 데이터 구성 단계를 수행하기 위해 팬더 데이터 프레임으로 변환하고 불필요한 열 "@type"및 "country")을 삭제 한 후 상위 5 개 행을 확인하여 모든 것이 올바르게 표시되는지 확인하십시오.
locs_df = df.from_records(locs_dict)
locs_df.drop(['@type', 'addressCountry'], axis = 1, inplace = True)
locs_df.head(n = 5)
결과를 저장하십시오 !!
df.to_csv(locs_df, "family_dollar_ID_locations.csv", sep = ",", index = False)
우리는 해냈다! 모든 아이다 호 패밀리 달러 매장의 쉼표로 구분 된 목록이 있습니다. 정말 타는 것입니다.
셀레늄 및 데이터 스크랩에 대한 몇 마디
셀레늄은 웹 페이지와의 자동 상호 작용을 위한 공통 유틸리티입니다. 때때로 사용해야 하는 이유를 설명하기 위해 Walgreens 웹 사이트를 사용하는 예를 살펴 보겠습니다. 요소 검사는 브라우저에 표시되는 코드를 제공합니다.
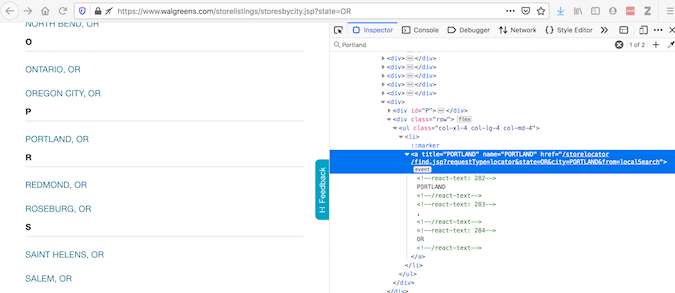
View Page Source는 어떤 요청을 얻을 수 있는지에 대한 코드를 제공합니다.
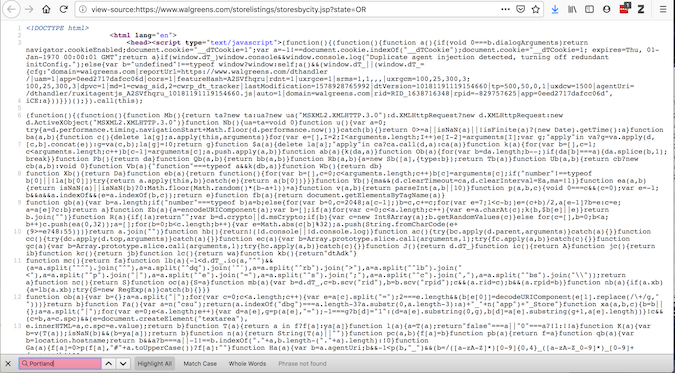
이 두 가지가 일치하지 않으면 소스 코드를 수정하는 플러그인이 있으므로 페이지가 브라우저에 로드 된 후에 액세스 해야 합니다. 요청은 그렇게 할 수 없지만 셀레늄은 할 수 있습니다.
Selenium은 컨텐츠를 검색하기 위해 웹 드라이버가 필요합니다. 실제로 웹 브라우저가 열리고 이 페이지 컨텐츠가 수집됩니다. Selenium은 강력합니다. 여러 가지 방법으로 로드 된 컨텐츠와 상호 작용할 수 있습니다 (문서를 읽으십시오). Selenium으로 데이터를 가져온 후 이전과 같이 BeautifulSoup을 계속 사용하십시오.
url = "https://www.walgreens.com/storelistings/storesbycity.jsp?requestType=locator&state=ID"
driver = webdriver.Firefox(executable_path = 'mypath/geckodriver.exe')
driver.get(url)
soup_ID = BeautifulSoup(driver.page_source, 'html.parser')
store_link_soup = soup_ID.find_all(class_ = 'col-xl-4 col-lg-4 col-md-4')
Family Dollar의 경우 Selenium이 필요하지 않았지만 렌더링 된 내용이 소스 코드와 다를 때 사용하십시오.
마무리
결론적으로 웹 스크래핑을 사용하여 의미 있는 작업을 수행 할 때 :
답이 궁금하다면 :
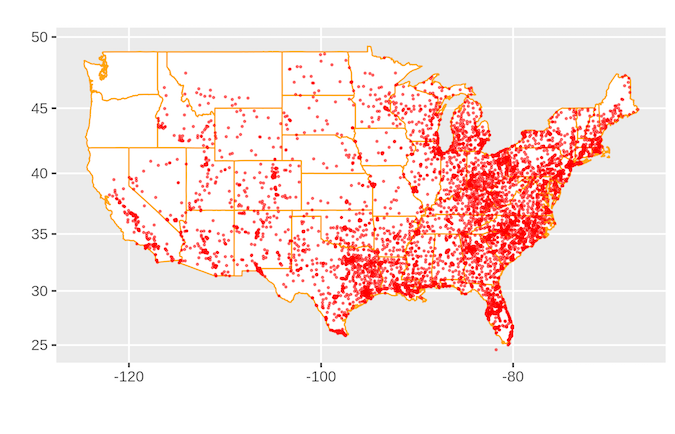
미국에는 많은 가족 달러 상점이 있습니다.
완전한 소스 코드는 다음과 같습니다.
import requests
from bs4 import BeautifulSoup
import json
from pandas import DataFrame as df
page = requests.get("https://www.familydollar.com/locations/")
soup = BeautifulSoup(page.text, 'html.parser')
# find all state links
state_list = soup.find_all(class_ = 'itemlist')
state_links = []
for i in state_list:
cont = i.contents[0]
attr = cont.attrs
hrefs = attr['href']
state_links.append(hrefs)
# find all city links
city_links = []
for link in state_links:
page = requests.get(link)
soup = BeautifulSoup(page.text, 'html.parser')
familydollar_list = soup.find_all(class_ = 'itemlist')
for store in familydollar_list:
cont = store.contents[0]
attr = cont.attrs
city_hrefs = attr['href']
city_links.append(city_hrefs)
# to get individual store links
store_links = []
for link in city_links:
locpage = requests.get(link)
locsoup = BeautifulSoup(locpage.text, 'html.parser')
locinfo = locsoup.find_all(type="application/ld+json")
for i in locinfo:
loccont = i.contents[0]
locjson = json.loads(loccont)
try:
store_url = locjson['url']
store_links.append(store_url)
except:
pass
# get address and geolocation information
stores = []
for store in store_links:
storepage = requests.get(store)
storesoup = BeautifulSoup(storepage.text, 'html.parser')
storeinfo = storesoup.find_all(type="application/ld+json")
for i in storeinfo:
storecont = i.contents[0]
storejson = json.loads(storecont)
try:
store_addr = storejson['address']
store_addr.update(storejson['geo'])
stores.append(store_addr)
except:
pass
# final data parsing
stores_df = df.from_records(stores)
stores_df.drop(['@type', 'addressCountry'], axis = 1, inplace = True)
stores_df['Store'] = "Family Dollar"
df.to_csv(stores_df, "family_dollar_locations.csv", sep = ",", index = False)
등록된 댓글이 없습니다.