Skipper는 개발자와 운영자 모두에게 네트워크 감시 기능을 향상 시킵니다.
이전 기사에서는 서비스 구성을 위한 오픈 소스 HTTP 라우터 및 리버스 프록시인 Skipper를 소개했습니다.
이 기사는 Skipper가 네트워크 가시성을 높이는 방법에 초점을 맞추고 확장 가능한 응용 프로그램 개발자와 그들이 운영하는 인프라 운영자 모두에게 이점을 설명합니다.
https://opensource.com/article/20/5/skipper
네트워크 가시성이란 무엇입니까?
가시성은 무엇이며 이를 지원하기 위해 무엇을 달성해야 합니까? Charity 전공은 트위터에서 좋은 답변을 제공합니다.
Skipper는 HTTP 라우팅 공급자로서 응용 프로그램 개발자에게 가시성을 제공하려고 합니다. 전자 상거래 소매업체인 Zalando에서 기능 팀의 개발자는 실패율 (%), 처리량 (초당 요청 또는 RPS) 및 대기 시간 (예 : p50, p99, p999)을 이해하기 위해 시스템을 모니터링 하려고합니다.
사용자 지정 프록시를 계측하려는 Skipper 라이브러리 사용자는 Skipper의 메트릭 패키지를 사용하여 프록시를 계측하고 사용자 지정 메트릭을 만들 수 있습니다.
운영자는 시스템이 일반적으로 특정 시점에서 어떻게 작동하는지 이해하기 위해 관찰력이 필요하므로 누군가 "어제 오전 2시 30 분에 무슨 일이 있었습니까?" 또는 "이 요청은 어떻게 처리됩니까?" Skipper는 백엔드 애플리케이션의 가시성을 높여 이러한 질문에 대한 답변을 제공 할 수 있습니다.
백엔드 애플리케이션 모니터링
이 기사의 목적을 위해 백엔드 애플리케이션을 Skipper HTTP 프록시 뒤에서 실행되는 임의의 HTTP 서비스로 정의합니다.
워크로드를 실행하는 애플리케이션 소유자는 대기 시간, 트래픽, 오류 및 채도의 4 가지 황금 신호를 모니터링 하려고 합니다.
Skipper와 같은 HTTP 라우터는 통화 경로에서 적절한 위치에 있어 백엔드에 지연, 트래픽 및 오류 중 네 가지 중 세 가지를 제공합니다.
그러나 채도는 실제로 복잡한 목표입니다. 노드, 제어 그룹 또는 응용 프로그램 수준에서 모니터링 해야 하므로 이 문서에서는 다루지 않습니다.
측정 항목
Skipper는 응답 대기 시간, RPS 처리량, 경로 및 집계 된 경로의 확인 및 실패율을 표시합니다. 이는 애플리케이션 소유자가 경보를 받아야 하는 기본 신호이므로 필요에 따라 조치를 취할 수 있습니다.
Skipper는 필요에 따라 다른 응용 프로그램 메트릭을 제공 할 수 있습니다. 지표는 호스트 헤더 또는 경로별로 수집 할 수 있습니다. -serve-host-metrics를 사용하여 Skipper를 시작하면 호스트 헤더별로 그룹화 된 메트릭을 수집하고 노출 할 수 있습니다.
자세한 내용이 필요하면 -serve-route-metrics를 사용하여 경로, 상태 코드 및 방법별로 메트릭을 분할 할 수 있습니다.
무료는 제공되지 않으며 더 많은 측정 항목이 항상 좋은 것은 아닙니다. Skipper 및 시계열 데이터베이스 (TSDB)에서 메모리 사용량이 있는 메트릭 저장 및 쿼리에 대한 비용을 지불합니다.
지표가 Coda Hale 또는 Prometheus 형식으로 노출되는지 여부를 선택할 수도 있습니다.
Coda Hale 지표는 pN (예 : p99)에 미리 집계 된 대기 시간을 노출합니다. 이러한 사전 집계 된 지표의 한 가지 단점은 모든 인스턴스에서 통계적으로 올바른 p99를 얻을 수 없다는 것입니다.
모든 Skipper 인스턴스에서 적절한 pN을 계산하려면 Prometheus를 사용하여 Skipper 인스턴스를 스크래핑 하는 것이 좋습니다.
그런 다음 Prometheus를 쿼리하여 대기 시간, 오류 및 처리량을 계산할 수 있습니다.
Latency
백엔드에 대한 응답 대기 시간을 얻으려면 그림 1에 표시된 PromQL 쿼리를 사용할 수 있습니다.이 쿼리는 마지막 분 동안 호스트 헤더별로 p99 대기 시간을 나눕니다.
Figure 1:
histogram_quantile(
0.99,
sum(rate(skipper_serve_host_duration_seconds_bucket{}[1m]))
by (le,host)
)
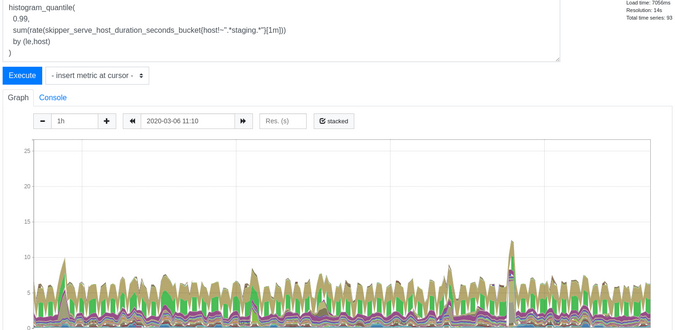
(Sandor Szuecs, CC BY-SA 4.0)
Traffic
처리량 데이터를 얻으려면 그림 2에 표시된 쿼리를 사용할 수 있습니다.이 PromQL 쿼리는 호스트 헤더별로 RPS 분할을 보여줍니다.
Figure 2:
sum(rate(skipper_serve_host_duration_seconds_count{}[1m])) by (host)
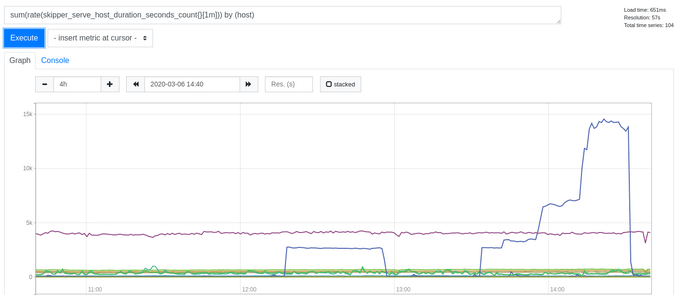
(Sandor Szuecs, CC BY-SA 4.0)
Errors
Skipper에는 오류를 모니터링 하기 위한 몇 가지 옵션이 있습니다. 호스트 헤더별로 HTTP 상태 코드 4xx 및 5xx 오류를 가져 오려면 그림 3에 표시된 쿼리를 사용하십시오.
Figure 3:
sum(rate(skipper_serve_host_duration_seconds_count{code=~"[45].."}[1m]))
by (host)
/
sum(rate(skipper_serve_host_duration_seconds_count{}[1m]))
by (host)
오류를 보고 싶다면 그림 4의 쿼리를 사용하십시오.
Figure 4:
sum(rate(skipper_serve_host_duration_seconds_count{code=~"[45].."}[10m])) by (host)
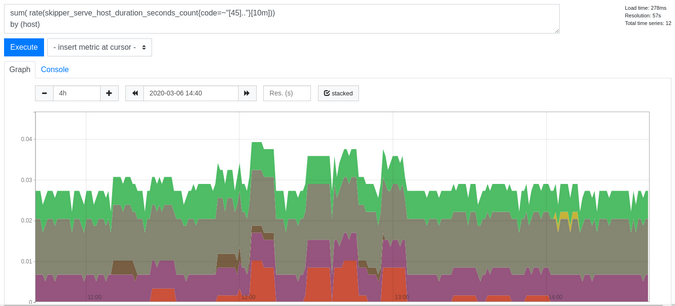
(Sandor Szuecs, CC BY-SA 4.0)
성공률을 보려면 그림 5의 쿼리를 사용하십시오.
Figure 5:
(
sum(rate(skipper_serve_host_duration_seconds_count{}[10m])) by (host)
- sum(rate(skipper_serve_host_duration_seconds_count{code=~"[45].."}[10m])) by (host)
) / sum(rate(skipper_serve_host_duration_seconds_count{}[10m])) by (host)
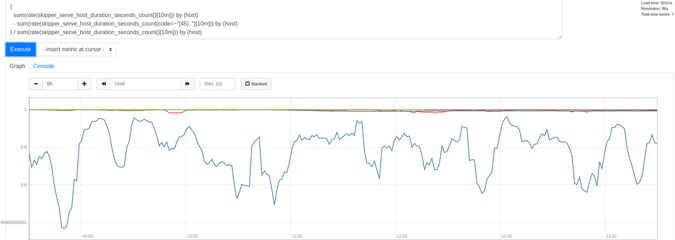
(Sandor Szuecs, CC BY-SA 4.0)
Access logs
Skipper는 매우 유용한 액세스 로그도 제공합니다. enableAccessLog 및 disableAccessLog 필터를 사용하여 개별 경로의 상태 코드별로 로그 출력을 제어 할 수 있습니다. 액세스 로그에는 개별 클라이언트로 다시 추적 할 수있는 데이터도 포함되어 있습니다. 예를 들어 unverifiedAuditLog 필터를 사용하여 클라이언트를 식별 할 JSON 웹 토큰 (JWT)의 일부를 로깅 할 수 있습니다. 이를 통해 애플리케이션 소유자는 어떤 클라이언트가 어떤 종류의 액세스 패턴을 가지고 있는지 이해할 수 있습니다.
Skipper는 JSON 또는 Apache 2 스타일 액세스 로그 형식의 구조적 로그를 지원합니다. Apache 형식은 사람이 읽기에 적합하며 사용할 수 있는 거대한 생태계가 있습니다. 머신으로 로그를 처리하려는 경우 JSON 형식을 사용할 수 있습니다.
종종 웹 상점과 같은 최종 사용자 웹 사이트에 여러 응용 프로그램 또는 서비스가 사용됩니다. 조사를 위해 단일 사용자 트랜잭션에 대한 모든 로그를보고자 하므로 오류를 이해하고 배후의 문제를 해결할 수 있습니다. 모든 응용 프로그램의 로그에 비즈니스 추적 ID가 있습니까? Zalando에서는 HTTP 헤더로 전달 된 flowID 식별자를 사용하여 이벤트 로그를 구현했습니다. Skipper에는 flowID 필터가 있으며 값을 액세스 로그에 기록합니다. 이를 통해 분산 추적과 같은 최신 툴킷 없이 하나의 비즈니스 트랜잭션에 대한 모든 액세스 로그를 쉽게 찾을 수 있습니다.
Distributed tracing
최신 가시성 툴킷에서 분산 추적이 중요합니다. 우리는 OpenTelemetry에서 제공 한 에코 시스템 (이전에는 OpenTracing 및 OpenCensus)으로 이 용어를 사용합니다.
분산 추적은 완전히 다른 분산 시스템 보기를 제공합니다. 예를 들어, 그림 6에 나와있는 폭포 형 차트 유형을 얻을 수 있습니다. 여러 기간 동안 서로 다른 작업을 수행하는 여러 서비스를 보여줍니다. 왼쪽의 초기 HTTP GET / 디스패치 범위는 두 가지 다른 범위, 즉 HTTP GET / 고객 호출 및 Driver :: findNearest Redis 작업을 엽니 다.
Figure 6:
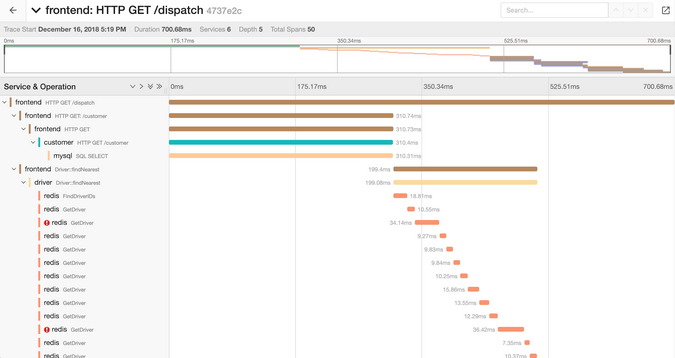
(Sandor Szuecs, CC BY-SA 4.0)
이것은 많은 가시성입니다!
Skipper의 분산 추적 지원에 대한 자세한 내용은 아래를 참조하십시오.
Operations
분산 서비스 운영자는 Edge 프록시가 어떻게 실행되고 있는지 확인하려고 합니다. 그들은 Skipper가 정상인지, 응용 프로그램에 대기 시간을 일으키는 지, 그렇다면 그렇다면 시간을 소비하는 것을 알고 싶어합니다. 또한 평균 복구 시간을 줄이기 위해 백엔드 문제와 HTTP 라우터 문제를 구별하려고 합니다.
대부분의 응용 프로그램은 메모리 및 CPU 사용량과 같은 핵심 메트릭을 제공해야 하지만 전체 비즈니스의 백본을 제공하는 중요한 구성 요소에는 충분하지 않습니다 (백엔드 대기 시간, RPS 처리량, 오류율, 연결 상태, 대기열 상태 및 재시작이 매우 중요 함) 중요하다.
Skipper는 Go로 작성되었으며 메모리, 가비지 수집 세부 정보, 스레드 수 및 고 루틴과 같은 몇 가지 흥미로운 런타임 메트릭을 제공합니다.
이러한 모든 메트릭은 지원 리스너로 내보내지며 기본값은 : 9911 / metrics입니다.
그림 7은 클러스터 전체 그래프 모음이 있는 Skipper 대시 보드를 보여줍니다. 첫 번째 행에는 처리량, 백엔드 대기 시간 및 프로세스 동시성에 대한 데이터가 표시됩니다. 이 그래프는 중요한 클러스터 패턴과 HTTP 라우팅 및 백엔드의 상태를 보여줍니다. 하드웨어 변경으로 인해 Go 런타임 또는 인스턴스 당 컴퓨팅 처리량이 사용중인 스레드 수를 변경할 수 있습니다. 두 번째 행에서 HTTP 상태 코드 2xx, 4xx 및 5xx를 보고 전체 오류를 보고 "정상"으로 간주되는 사항을 이해할 수 있습니다.
Figure 7:
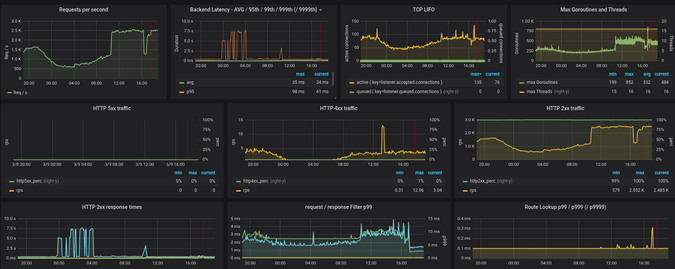
(Sandor Szuecs, CC BY-SA 4.0)
그림 8은 추가 런타임 및 용량 세부 정보를 보여줍니다. 호스트 헤더별로 분할 된 요청을 보여주는 그래프를 통해 애플리케이션에 대한 액세스 패턴을 식별 할 수 있습니다.
Figure 8:
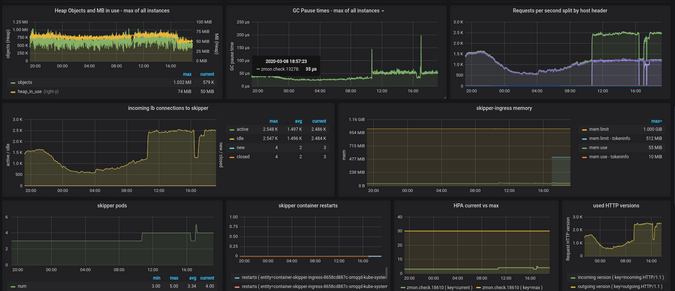
(Sandor Szuecs, CC BY-SA 4.0)
그림 9의 맨 아래 부분은 서로 다른 두 컨테이너의 CPU 사용량을 보여줍니다.
상단에는 필터와 LIFO (last in, first out) 대기열이 있으며 자세한 설명이 필요합니다.
예를 들어, 사용자가 compress () 필터를 사용하기 시작하면 패킷 이동 뿐만 아니라 압축 알고리즘에 CPU를 사용하기 때문에 응답 필터가 느리고 CPU 사용량이 증가 할 수 있습니다.
개발자가 webhook() 또는 oauth *와 같은 외부 API를 호출하는 인증 필터를 사용하기 시작하면 요청 필터 런타임도 이러한 엔드 포인트에 대한 왕복을 계산합니다.
이 정보는 관찰 된 애플리케이션 대기 시간이 느린 tokeninfo 엔드 포인트와 같은 보다 글로벌 한 것의 부작용인지 여부를 보여줍니다.
그림 9는 17:00에 tokeninfo CPU 사용량에 대한 새로운 지표가 있음을 보여줍니다.
토큰 정보 인증 끝점을 사이드카로 배포하여 필터 대기 시간을 줄였습니다. 또한 Skipper CPU 사용량.
Figure 9:
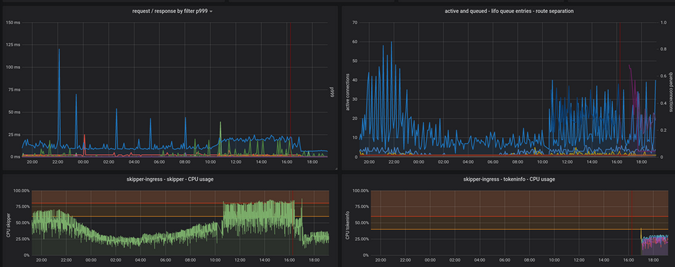
(Sandor Szuecs, CC BY-SA 4.0)
Distributed tracing
그림 6의 폭포 형 차트를 다시 살펴보면 애플리케이션 전체에서 요청 플로우를 볼 수 있습니다. 해당 정보는 추적 라이브러리에서 제공됩니다. Skipper는 현재 Instana, Jaeger 및 Lightstep 추적 공급자를 지원하므로 SaaS 공급자 또는 오픈 소스 버전을 사용하도록 선택할 수 있습니다.
분산 추적 제공자가 제공하는 추적은 훌륭하지만 세부 사항을 살펴보면 폭포 형 차트만으로도 훨씬 많은 것을 얻을 수 있습니다.
분산 추적에서 추적은 연결된 범위로 구성됩니다. 스팬에는 서비스, 작업 및 기간이 있지만 태그 및 로그와 같은 메타 데이터도 포함 할 수 있습니다. Skipper를 사용하면 환경, 호스트 이름, 클러스터 이름 또는 클라우드 공급자와 같은 프로세스 글로벌 태그를 설정할 수 있습니다.
추적을 필터링하고 그룹화 하는 데 유용합니다.
스키퍼는 각 작업마다 5 개의 범위를 제공합니다.
예를 들어, 그림 10의 요청 필터 범위에서 로그의 모든 개별 경로 필터를 실행하는 데 소요 된 시간을 볼 수 있습니다.
Figure 10:
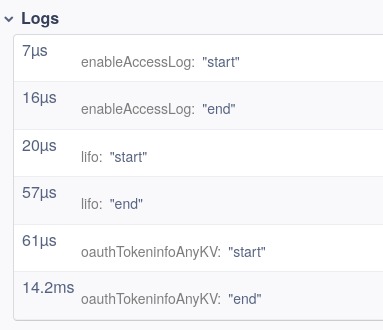
(Sandor Szuecs, CC BY-SA 4.0)
프록시 범위에서 로그는 다이얼, TCP / IP 연결 및 TLS 핸드 셰이크, 백엔드로의 HTTP 왕복 및 클라이언트로의 헤더 및 데이터 스트리밍 시간을 보여줍니다. 계측 된 백엔드가 없어도 그림 11에서 볼 수 있듯이 백엔드는 약 90ms, dial_context, TCP / IP 및 TLS 핸드 셰이크는 1.04ms가 걸렸습니다.
Figure 11:
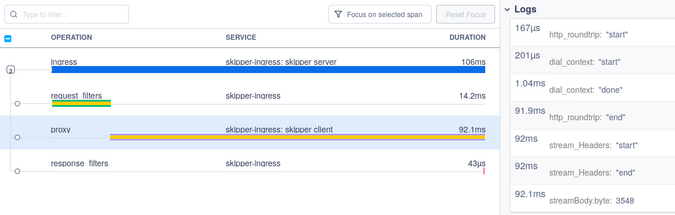
(Sandor Szuecs, CC BY-SA 4.0)
Go 응용 프로그램을 계측해야 하는 경우 클라이언트 범위에서 자세한 로그를 제공하는 Skipper HTTP 클라이언트를 사용할 수 있습니다. 예를 들어, 그림 12는 클라이언트를 사용하는 tokeninfo 및 auth 필터 범위를 보여줍니다.
Figure 12:
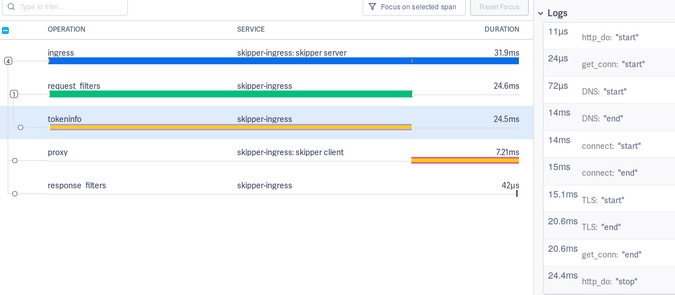
(Sandor Szuecs, CC BY-SA 4.0)
자세한 내용은 Skipper의 OpenTracing 설명서를 참조하십시오.
Routing table
다른 HTTP 라우터와 마찬가지로, Skipper에는 라우팅 테이블 또는 보다 정확하게는 라우팅 트리가 있습니다 (이전 기사에서 설명했듯이). 트리 구조를 사용하면 경로 수를 확장하고 조회 중에 성능을 향상 시킬 수 있습니다. 이를 통해 Skipper는 한 인스턴스에서 600,000 개 이상의 경로로 실행할 수 있습니다.
운영자는 때때로 라우팅 문제를 조사해야 합니다. 구성 소스에서 작업 할 필요는 없지만 라우팅 트리를 온라인으로 보는 것이 좋습니다. -support-listener를 사용하면 Skipper를 사용하여 인스턴스의 현재 라우팅 테이블을 덤프 할 수 있습니다. 그림 13은 라우팅 테이블의 일부를 덤프하는 방법을 보여줍니다. 이 경우 offset = 10 및 limit = 1을 사용하면 10 번째 경로 만 인쇄됩니다.
Figure 13:
% curl "localhost:9911/routes?offset=10&limit=1"
kube_default__foo__foo_teapot_example_org_____foo: Host(/^foo[.]teapot[.]example[.]org$/) && PathSubtree("/")
-> enableAccessLog(4, 5)
-> lifo(2000, 20000, "3s")
-> setRequestHeader("X-Foo", "hello-world")
-> <roundRobin, "http://10.2.0.225:9090", "http://10.2.1.244:9090">;
Debugging requests
이전 기사에서는 Skipper 필터가 백엔드로 전달 된 요청을 변경할 수 있음을 보여주었습니다. 그러나 발신 요청을 어떻게 조사합니까? 사람들은 종종 디버그 로그를 사용하거나 시스템에 SSH를 사용하고 tcpdump를 사용하여 나가는 요청을 찾기 위해 모든 것을 덤프 합니다.
Skipper는 변환 된 요청을 검사하는 더 좋은 방법을 제공합니다. Skipper는 디버그 리스너 -debug-listener = : 9922를 사용하여 들어오고 나가는 요청에 대한 정보를 표시 할 수 있습니다. 그림 14에서 발신 요청이 그림 13의 필터 setRequestHeader ( "X-Foo", "hello-world")에 의해 추가 된 X-Foo : hello-world 요청 헤더를 적용한 것을 볼 수 있습니다.
Figure 14:
% curl -s http://127.0.0.1:9922/ -H"Host: foo.teapot.example.org" | jq .
{
"route_id": "kube_default__foo__foo_teapot_example_org_____foo",
"route": "Host(/^foo[.]teapot[.]example[.]org$/) && PathSubtree(\"/\") -> enableAccessLog(4, 5) -> lifo(2000, 20000, \"3s\") -> setRequestHeader(\"X-Foo\", \"hello-world\") -> <roundRobin, \"http://10.2.0.225:9090\", \"http://10.2.1.244:9090\">",
"incoming": {
"method": "GET",
"uri": "/",
"proto": "HTTP/1.1",
"header": {
"Accept": [
"*/*"
],
"User-Agent": [
"curl/7.49.0"
]
},
"host": "foo.teapot.example.org",
"remote_address": "127.0.0.1:32992"
},
"outgoing": {
"method": "GET",
"uri": "",
"proto": "HTTP/1.1",
"header": {
"Accept": [
"*/*"
],
"User-Agent": [
"curl/7.49.0"
],
"X-Foo": [
"hello-world"
]
},
"host": "foo.teapot.example.org"
},
"response_mod": {
"header": {
"Server": [
"Skipper"
]
}
},
"filters": [
{
"name": "enableAccessLog",
"args": [
4,
5
]
},
{
"name": "lifo",
"args": [
2000,
20000,
"3s"
]
},
{
"name": "setRequestHeader",
"args": [
"X-Foo",
"hello-world"
]
}
],
"predicates": [
{
"name": "PathSubtree",
"args": [
"/"
]
}
]
}
마무리
이 기사에서는 Skipper를 사용하여 HTTP 라우팅 시스템의 가시성을 높이는 방법을 보여주었습니다.
이 정보가 관찰 성을 높이는 데 필요한 정보를 제공하기를 희망하지만 궁금한 점이 있으면 아래 의견에 알려주십시오.
등록된 댓글이 없습니다.