웹 사이트 스크래핑은 일반적인 툴셋의 일반적인 문제입니다. 오늘날 두 가지 접근 방식이 웹을 지배합니다.
프로그래밍 방식으로 실제 브라우저를 구동하는 첫 번째 방법은 자동화 된 웹 사이트 테스트를 실행하거나 사이트의 스크린 샷을 캡처하는 프로젝트에서 일반적입니다.
https://medium.com/@dylan.sather/scrape-a-site-with-node-and-cheerio-in-5-minutes-4617daee3384
두 번째 접근 방식에는 한계가 있습니다. 예를 들어 Cheerio는 "브라우저가 아닙니다"및 "비주얼 렌더링을 생성하지 않고 CSS를 적용하거나 외부 리소스를 로드하거나 JavaScript를 실행하지 않습니다". 그러나 이 방법은 간단하고 종종 충분합니다. 특히 스크랩이 어떻게 작동하는지 배우는 경우에 충분합니다.

Scraping 101 : 샘플 HTML 가져 오기, 기본 텍스트 추출
이 자습서에서는 Cheerio 및 Node.js를 사용하여 웹 사이트를 긁어 보겠습니다. Pipedream에서 코드를 실행하겠습니다 (Pipedream 팀 구성 중). 또한 페이지의 일부 컨텐츠가 포함 된 이메일을 자신에게 보내는 방법을 보여 드리며, 나중에 분석하기 위해 Amazon S3 버킷에 저장하는 방법을 살펴 보겠습니다.
이 학습서를 최대한 활용하려면 기본 노드 (또는 JavaScript)를 읽고 HTTP를 이해하는 방법을 알아야 합니다.
Pipedream은 무엇입니까?
Pipedream은 서버를 관리하지 않고도 모든 노드 코드를 무료로 실행할 수 있는 개발자 자동화 플랫폼입니다. 코드를 작성하면 Pipedream에서 코드를 실행합니다. 코드는 크론 작업으로 실행되거나 HTTP 요청 (일부 SaaS 서비스의 웹 후크)에 의해 트리거 될 수 있습니다.

Pipedream에 대한 간단한 개요. 자세한 내용을 보려면 GIF를 클릭하십시오.
Pipedream 전에 프로그래밍 부트 캠프를 가르쳤습니다. 학생들은 웹 사이트를 긁어 내고 Twitter의 데이터를 분석하고 로컬 컴퓨터에서 매우 복잡한 앱을 작성하는 방법을 배웠습니다. 그러나 동일한 응용 프로그램을 cron 작업 또는 공개 웹 사이트로 실행할 수 있는 장소에 배포하는 데 몇 시간이 걸렸습니다. 그들은 결코 서버를 운영하거나 클라우드 플랫폼과 함께 일하지 않았기 때문에 작업을 진행하기가 더 어려워졌습니다.
Pipedream은 노드 코드를 실행하기 위한 호스팅 환경을 제공합니다. 프로비저닝 할 서버 또는 클라우드 리소스가 없습니다. Github 또는 Google에 가입하고 코드를 작성하면 해당 코드가 실행됩니다. 기본 제공 로깅, 오류 처리 등이 있습니다. AWS Lambda 또는 기타 클라우드 기능 서비스와 매우 유사하지만 사용하기가 더 쉽습니다.
그것에 대해 충분합니다. 코드를 보자!
1 단계 - 사용 Axios의와 힘내라는 긁어 example.com
https://example.com은 가장 간단한 웹 페이지이므로 스크래핑 기본 사항을 강화할 수 있는 훌륭한 사이트입니다.

이 사이트를 긁어 내기 위해 2 npm 패키지를 사용합니다.
코드는 다음과 같습니다.
| const axios = require("axios") | |
| const cheerio = require("cheerio") | |
| async function fetchHTML(url) { | |
| const { data } = await axios.get(url) | |
| return cheerio.load(data) | |
| } | |
| const $ = await fetchHTML("https://example.com") | |
| // Print the full HTML | |
| console.log(`Site HTML: ${$.html()}\n\n`) | |
| // Print some specific page content | |
| console.log(`First h1 tag: ${$('h1').text()}`) |
fetchHTML 함수는 axios.get을 사용하여 전달한 URL에 대해 사이트의 HTML을 다운로드하여 HTTP GET 요청을 작성합니다. cheerio.load는 해당 HTML을 DOM 객체로 로드하여 웹 사이트 콘텐츠를 구문 분석 할 수 있습니다.
JQuery에 익숙하다면 Cheerio와 함께 집에 있는 것처럼 편안할 것입니다. Cheerio는 DOM (웹 페이지)에서 특정 요소를 선택하는 동일한 개념을 사용하여 $객체를 구현합니다.
$.html()은 웹 페이지를“렌더링”합니다. 즉, 페이지에서 HTML의 문자열 표현을 리턴합니다.
$('h1').text()는 첫 번째 h1 태그 내의 텍스트를 반환합니다. 이와 같은 다른 선택기를 사용하여 일부 조건을 충족하는 요소 (예 : 일부 클래스 또는 ID가 있는 요소)를 찾은 다음 add 또는 remove와 같은 메소드를 사용하여 읽거나 수정할 수 있습니다. 자세한 내용은 Cheerio 문서를 참조하십시오.
Pipedream에서 이 코드 실행
이 코드를 실행하여 어떻게 작동하는지 봅시다. 이 Pipedream 스크래핑 워크 플로우를 새 탭에서 여십시오.
이 워크 플로에는 다음 두 단계가 있습니다.
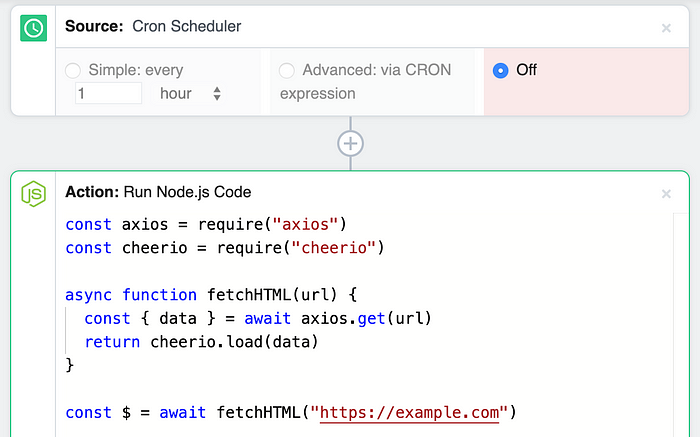
스케줄에 따라 이 노드 코드를 실행하십시오.
Cron 스케줄러 소스를 사용하면 일정에 따라 모든 코드를 실행할 수 있습니다. 소스 아래의 Run Node.js 코드 단계에는 위에서 검토 한 코드가 포함됩니다.
Pipedream 계정에서이 워크 플로우의 사본을 작성하려면 오른쪽 상단의 녹색 포크 단추를 클릭하십시오.

가입하지 않은 경우 메시지가 표시됩니다. 로그인은 Github 또는 Google 계정을 통해 이루어집니다. 이 무료 한 달에 2500 만 회까지 워크 플로우 실행할 수 있습니다.
이 워크 플로의 코드는 공개입니다. 워크 플로의 URL을 다른 사람과 공유 할 수 있으며 나와 같은 방식으로 분기하여 사용할 수 있습니다. 그러나 스크래핑 코드가 실행되면 모든 로그와 데이터가 계정의 개인 정보입니다.
크론 작업은 기본적으로 해제되어 있습니다. 이를 통해 코드를 켜기 전에 테스트하고 수정할 수 있습니다. 워크 플로우를 수동으로 실행하려면 지금 실행 버튼을 클릭하십시오.

지금 실행을 클릭하면 작업이 완료되면 로그가 표시됩니다
버튼을 누르면 분기 된 워크 플로가 실행됩니다. nxios 또는 Cheerio를 설치할 필요가 없습니다. 코드를 어딘가에 배포 할 필요가 없습니다. 정말 멋진.
완료되면 실행하는 데 걸린 시간이 표시됩니다.
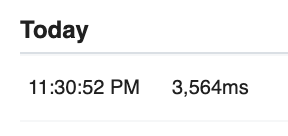
코드 단계의 맨 아래로 스크롤 하면 https://example.com에서 가져온 HTML 및 h1 태그가 표시됩니다.

이 포크는 당신이 수정할 것입니다. https://example.com URL을 자신의 URL로 변경하십시오. Cheerio 선택기를 사용하여 필요한 콘텐츠 만 얻은 다음 코드를 테스트하려는 경우 언제든지 저장하고 지금 실행하십시오.
코드가 좋아 보인다면 Cron 스케줄러 소스에서 적절한 옵션을 선택하여 원하는 때에 cron 작업이 실행되도록 예약 할 수 있습니다.
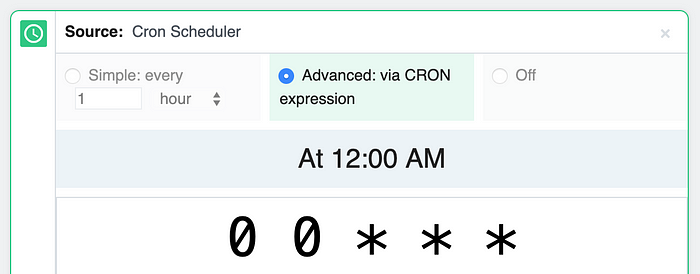
cron 표현식을 사용하여 모든 빈도로 작업을 예약 할 수 있습니다
문서에서 크론 작업에 대해 자세히 알아보십시오.
2 단계 — 어딘가에 결과 보내기
방금 파싱 한 콘텐츠를 console.log 이상으로 수행하고 싶을 것입니다. 내용의 일부를 이메일로 보내거나 나중에 분석 할 수 있도록 저장할 수 있습니다.
다음 두 가지 예를 살펴 보겠습니다.
페이지 내용을 이메일로 보내기
이 Pipedream 워크 플로우는 위와 동일한 스크래핑 로직을 구현하지만 사이트의 h1 태그 컨텐츠를 이메일로 보냅니다. 위와 같이 해당 워크 플로우를 분기하고 지금 실행을 클릭 할 수 있습니다.
이 코드는 :

이 이메일을 보냅니다 :

$send.email은 모든 코드 단계에서 사용할 수 있는 내장 Pipedream 기능으로, 이메일을 보내는 데 사용할 수 있습니다. 위에서와 같이 텍스트 속성을 전달하여 일반 텍스트 본문을 보내거나 html로 HTML 전자 메일을 보내십시오. $send.email에 대한 자세한 내용은 여기를 참조하십시오.
기본 제한 사항은 자신에게만 이메일을 보낼 수 있다는 것입니다 (가입 한 계정과 연결된 이메일 주소). 다른 사람에게 이메일을 보내야 하는 경우 Nodemailer 패키지 또는 Sendgrid 또는 Mandrill과 같은 트랜잭션 이메일 서비스를 사용할 수 있습니다.
Amazon S3에 결과 저장
이 워크 플로우는 위와 동일한 스크 레이 핑 로직을 구현하지만 Amazon S3 버킷에 스크랩 한 페이지의 전체 HTML도 저장합니다.
Amazon S3를 사용하면 HTML 문서, JSON 등 모든 데이터를 클라우드에 저렴하고 안전하게 저장할 수 있습니다. 웹 스크래핑에서 얻은 데이터를 저장하고 분석해야 하는 경우 S3와 같은 곳에 저장하는 것이 일반적입니다.
이 워크 플로우를 사용하려면 데이터를 저장하려는 기존 S3 버킷이 필요합니다. 또한 Pipedream에서 데이터를 저장할 수 있도록 이 버킷 정책을 해당 버킷에 추가해야 합니다.

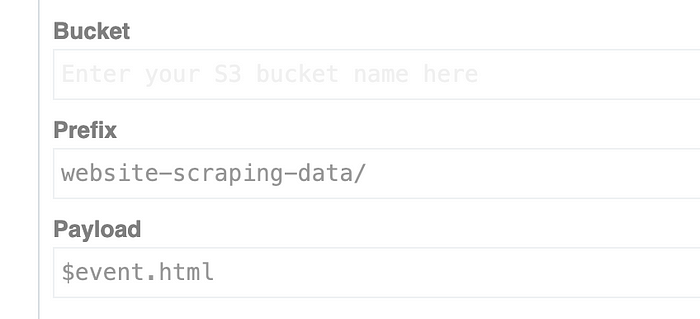
버킷 필드에 버킷 이름을 추가하십시오. 접두사 및 페이로드 필드도 수정할 수 있습니다.
위에서와 같이 작업을 실행하려면 지금 실행을 클릭하십시오. 데이터가 S3 버킷으로 전달되는 데 약 60 초가 걸립니다. S3 조치 아래의 결과 섹션에 성공 메시지가 표시되면 다음을 수행하십시오.

웹 사이트 스크랩 핑 데이터 접두사 안에 버킷의 HTML이 표시되어야 합니다.
코드 단계에서 $ event 객체의 속성에 HTML을 저장했습니다.
$event.html = $.html()
$event (“달러 이벤트”)는 워크 플로 단계간에 데이터를 저장하는 데 사용할 수 있는 JavaScript 객체입니다. 여기에서 사이트의 HTML을 $event의 html 속성에 저장 한 다음 S3 작업의 페이로드 필드에서 이를 참조합니다.
사용자가 퍼블릭 워크 플로우를 볼 때 S3 버킷의 이름은 보이지 않지만 접두사 및 페이로드 매개 변수 (예 : $ event.html)는 다른 사람들이 해당 기본값을 사용할 수 있도록 합니다. 예를 들어, 워크 플로에 대한 공개 뷰에서 다음과 같이 표시됩니다.
더 알아보기
axios와 Cheerio에는 이러한 도구에 대해 자세히 알아볼 수 있는 자세한 문서가 있습니다. 위의 코드에 대해 궁금한 점이 있으면 아래에 자유롭게 의견을 보내십시오.
등록된 댓글이 없습니다.